

4月初旬はソメイヨシノの開花に心が躍る.古い歌にあるように,
世の中にたえてさくらのなかりせば春の心はのどけからまし
あっという間に散っていく様は日本人の心を捉えて離さない.この桜の開花日の予測は気象庁でも行われている.
桜だけではない.生物季節観測の情報では各種の植物,動物を観測しており,過去のデータを公表している.
時節柄,過去の桜開花日をダウンロードして検索しやすいようにしようと考えた.
ファイルは最初に置いておく.好きに使ってくれて構わない.
関連記事
テキストファイルから SQL Server に気象データをインポートする
Google FormからSQL Serverへデータを移行するには
生物季節観測値の種目
気象庁では下表のように 57 種の生物について 65 の事象を観測している.主な植物については地方気象台の敷地内に観測用の植物を植え,標本木として観測している.
| 生物名 | 事象 |
|---|---|
| あじさい | 開花 |
| あんず | 開花 |
| あんず | 満開 |
| いちょう | 発芽 |
| いちょう | 黄葉 |
| いちょう | 落葉 |
| うめ | 開花 |
| かえで | 紅葉 |
| かえで | 落葉 |
| かき | 開花 |
| からまつ | 発芽 |
| ききょう | 開花 |
| くり | 開花 |
| くわ | 発芽 |
| くわ | 落葉 |
| さくら | 開花 |
| さくら | 満開 |
| さざんか | 開花 |
| さるすべり | 開花 |
| しだれやなぎ | 発芽 |
| しば | 発芽 |
| しろつめくさ | 開花 |
| すいせん | 開花 |
| すすき | 開花 |
| すみれ | 開花 |
| たんぽぽ | 開花 |
| チューリップ | 開花 |
| つばき | 開花 |
| でいご | 開花 |
| てっぽうゆり | 開花 |
| なし | 開花 |
| のだふじ | 開花 |
| ひがんざくら | 開花 |
| ひがんざくら | 満開 |
| ひがんばな | 開花 |
| もも | 開花 |
| やまつつじ | 開花 |
| やまはぎ | 開花 |
| やまぶき | 開花 |
| ライラック | 開花 |
| りんご | 開花 |
| あきあかね | 初見 |
| あぶらぜみ | 初鳴 |
| うぐいす | 初鳴 |
| えんまこおろぎ | 初鳴 |
| かっこう | 初鳴 |
| きあげは | 初見 |
| くさぜみ | 初鳴 |
| くまぜみ | 初鳴 |
| さしば南下 | 初見 |
| しおからとんぼ | 初見 |
| つくつくほうし | 初鳴 |
| つばめ | 初見 |
| とかげ | 初見 |
| とのさまがえる | 初見 |
| にいにいぜみ | 初鳴 |
| にほんあまがえる | 初鳴 |
| にほんあまがえる | 初見 |
| はるぜみ | 初鳴 |
| ひぐらし | 初鳴 |
| ひばり | 初鳴 |
| ほたる | 初見 |
| みんみんぜみ | 初鳴 |
| もず | 初鳴 |
| もんしろちょう | 初見 |
データファイルはPDFなのだが…
読めない.もっと言うと,マシンリーダブルでない.スペースで見栄えだけ揃えました,という感じがありありと見て取れる.テキストのないPDFファイルからテキストを抽出するにはで書いた気がするが,今どきこんな形のファイルをネット上に公開していて恥ずかしくないのか,と小一時間問い詰めたくなる.
気象庁は国民にデータを公開するとはどういうことか,分かってない
ダウンロードした PDF を開き,メモ帳にコピペしてテキストファイルで保存.それを EXCEL で読み込もうとして,詰んだ.
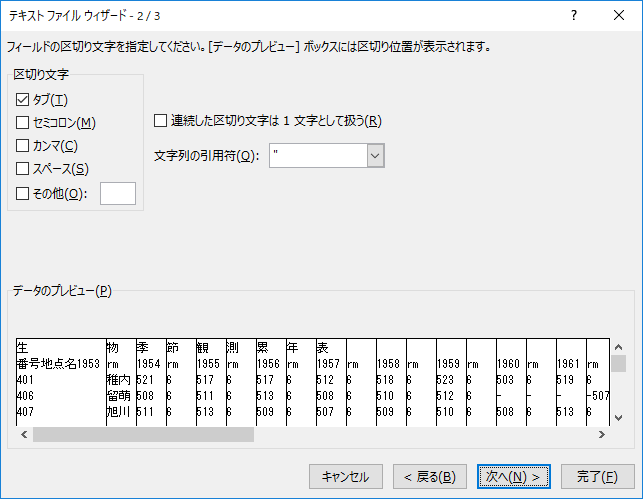
テキストファイルウィザードでも対応できない

.txtファイルを開く時のダイアログ.スペース区切りのテキストファイルには要注意だ.
データの区切り位置がずれる!
もうね,呆れて何も言えない.言えないが,言わせてもらう.

こんな不揃いのデータを公開して,恥ずかしくないのか?
せめて .csv ファイルにしてくれ.マシンリーダブルであるというのは,そういうことだ.ダウンロードしたらすぐ Excel で開いてデータベースに取り込みたいんだよ,こっちは.何なら直接データベースに突っ込みたい.
この手の官僚仕事にはうんざりしている.
Wordで置換してみたら?
ふと,Word の置換を使えばいいのではないかと思いついた.スペースをタブに置換してやればよい.物は試しだ.

ビンゴ!
行けそうな気がしてきた.そのままテキストファイルで保存.Excelに戻る.
マイナス記号が先頭についているデータもあるが,何とかなるだろう.

データの位置がまるごとずれている
ワークシートをスクロールしていって,はたと考え込んだ.番号地点の右側,何もデータのない箇所が複数ある.

これはどうしたものか?結論から言うと,直下の領域を丸ごとカットアンドペーストすればよかった.なんでこうなったのかよく分からないのだが.
空白行を削除
空白行をまとめて削除する.ここらへんは機械的な作業だ.サクサク済ませる.
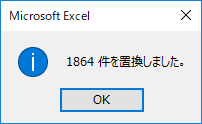
マイナスを削除する
マイナスの付いたところ,どうせデータベースには入らないんだから削除しよう.置換で一括削除する.1864件.
データのズレ,手動で直すか?
さっきマイナスの付いていたデータでセル位置がずれている.データは400件近くある.手動で直すのは大変だ.
さて,どうする?ワークシートの一番右側に注目する.ずれている行は列の最後のデータが欠損している.ここを抽出すれば良さそうだ.
いったん,テーブルに変換
目的は空白のセルのみにするためだ.列数は48.最後の列48にフィルターをかけて空白のみを抽出する.336行抽出された.なんだ,ほとんど全部じゃないか.
これは,悪手だ
データの殆どを手動で直すなんて馬鹿げている.何か他の方法を探そう.
最初にスペースをタブに置換した時を思い出せ
マイナスのついた数字があったな?あれが鍵だ.こういう時に正規表現で置換できるといいんだが.
もう一度,実データを見直す
迷ったら現場に立ち返る
一晩考えた後,くだんの PDF ファイルを見直す.マイナスの後,rm 列のところが空欄になっている.メモ帳に貼り付けたデータではマイナスの直後に数値が来ている.ここにヒントがあった.
マイナスの後にスペースを付け足せばよいのでは?
Word で.txt ファイルを開く.「ホーム」タブの「編集」から「置換」を選んでクリック.
「検索する文字列」には半角のハイフンをキーボードから入力する.
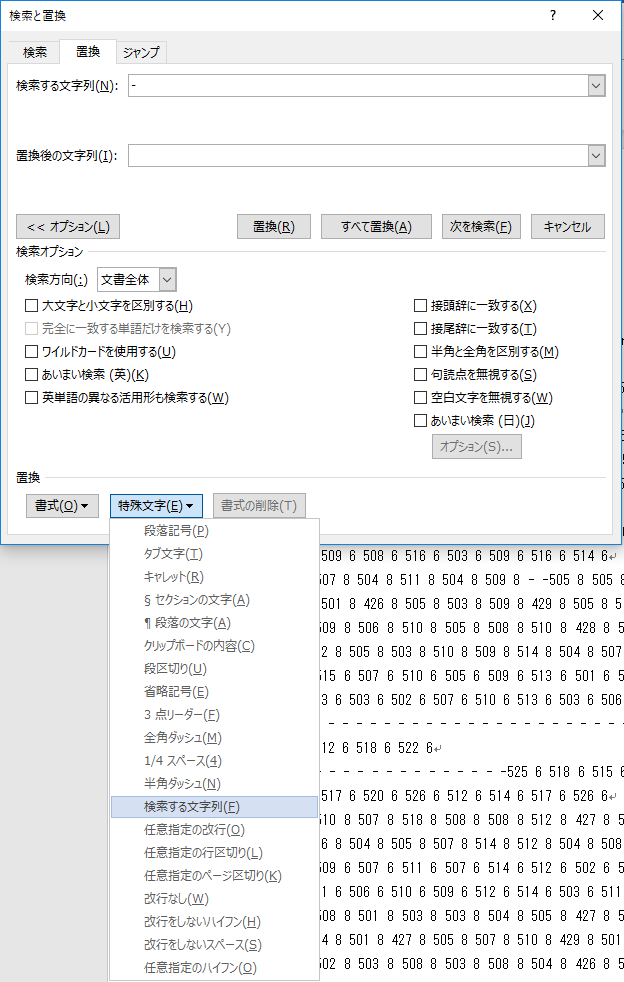
「置換後の文字列」に「特殊文字」から「検索する文字列」を選ぶ.同じ文字列で置換してどうする?と思うかも知れないが,これは正規表現エンジンにも実装されている重要な機能だ.
さらにキーボードから半角スペースをタイプする.ダイアログはこうなる.「^&」の後に「スペース」があるのがミソだ.
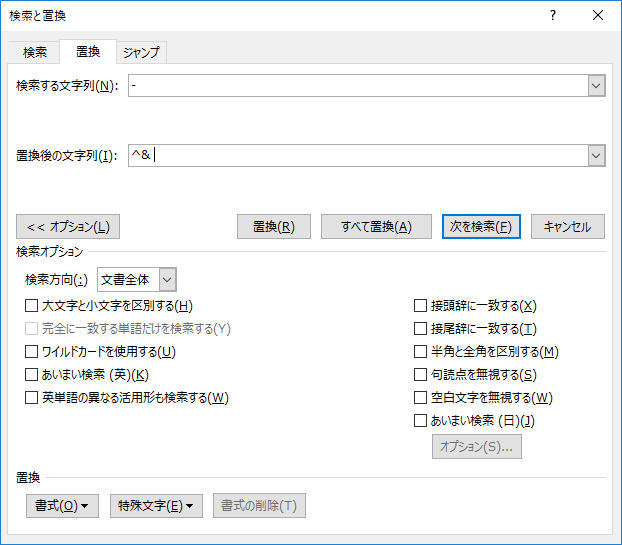
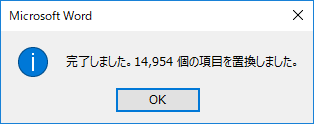
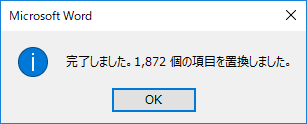
「全て置換」をクリック.1872件置換された.
スペースをタブで置換
次はスペースをタブで置換する.「検索する文字列」に「特殊文字」から「全角または半角の空白」を選ぶ

「置換後の文字列」は「特殊文字」から「タブ文字」を選ぶ.
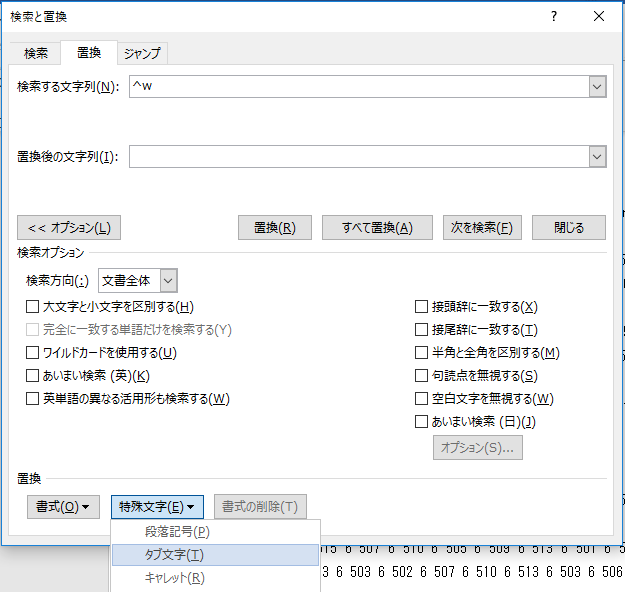
ダイアログとしてはこうなる.
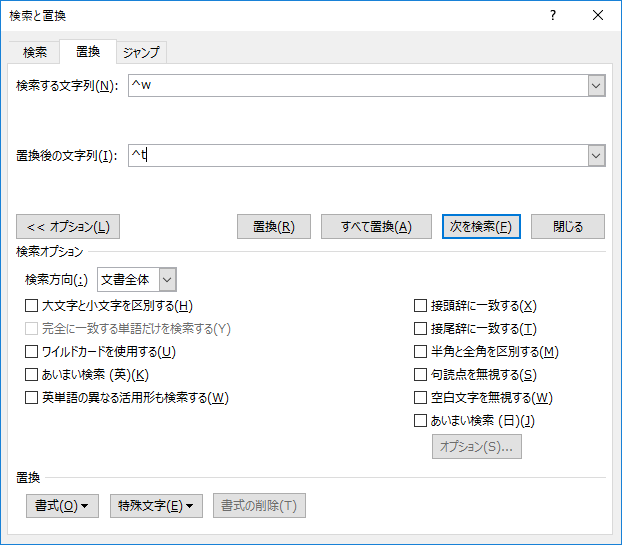
「全て置換」すると 15,133 件が置換された.
何とかデータの位置は揃ってきた.しかし…
相変わらず地点とデータのブロックがずれているのは直っていないが,だいぶマシになってきた.EXCEL で開くと,ところどころ先頭の位置がずれている行がある.
よく見ると,データの先頭位置が右に一個ずれている.その分,右端のセルが一個右にはみ出している.
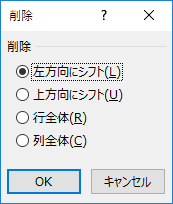
結論から言うと,手動でセル削除した.該当するセルを複数同時に削除しても大丈夫だ.気をつけるのは必ず「左方向にシフト」にすること.デフォルトでは「上方向にシフト」となっている.ここを間違えると取り返しがつかなくなる.
全体を俯瞰する
ここで一息ついて,データ全体を俯瞰してみよう.「表示」タブから「ズーム」を選び,倍率を「25%」にする.

はみ出していたり,凹んだりしている箇所はないか?なさそうだ.ここまで来てやっと前処理が整った.
ページごとの行数は同じか?
検索でページ先頭のマーカーとして残しておいた「番号」の文字を全て検索する.大事なのはセルの位置だ.差分がすべて52になっているのが見て取れる.
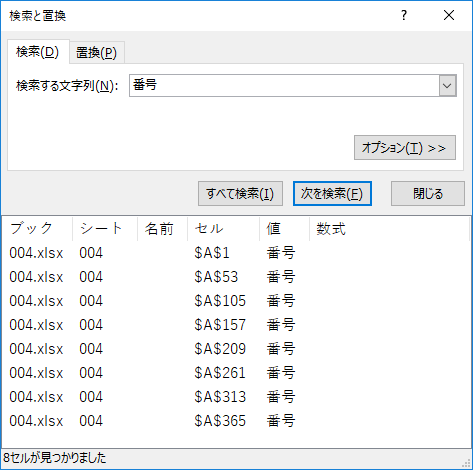
地点名の並び順は同じか?
次に「地点名」の並び順が同じか確認する.試しに「稚内」を全て検索してみる.セル位置の差分は104.どうやら他の地点名も同じと見て良さそうだ.
オリジナルの PDF は 8 ページだったが, コンパクトにまとめられそうだという見通しが立った.
カットアンドペーストで一つの塊に並べ替える
この文書は何層にも折り畳まれた構造をしている.その折り畳まれた構造を解きほぐし,第一正規形に持っていくのが目的だ.

とにもかくにも,地点名と年別になっているテキストの塊をカットアンドペーストでより単純な形にしていく.

手動とプログラムの使い分けを見極めよう
これ以上手動で対応は無理,でもプログラムを組むには複雑すぎる.そういうボーダーラインがある.プログラムが得意なのは単純な繰り返し作業だ.
その単純な形にまで手動で持っていけば,後はルーチン化できる.ここまで失敗を含めた試行錯誤の過程を書き記してきたのは,この国のデータに対するリテラシーを高めたいという思いからである.
データは前処理が重要だ.前処理に手間と時間の 90 % が取られている.その時間と手間が惜しい.この記事を読んだ人は,官僚の作るデータがいかに使いにくいか,よく分かっていると思う.
すぐに使える形でデータを公開すること.すぐに使える形とは第一正規形だ.
不満はこのくらいにして,手を動かしていこう.
実際の処理は手間隙かかる
年月日の扱いに注意
処理に入る前に年月日の記述について確認しておく.各ページの最後に繰り返し記載されているが,
最早・最晩以外の起日については,年界を越えて前年もしくは翌年にずれ込んで発生した現象についても,当年の欄に発生月日が記述される.
おい,ちょっと待て.単純に年と月日を結合して DATE 型のデータを作成しようとしていたのに.余計な手間かけさせやがって.
当年か,前年か,どう判別する?
ワークシートをテーブルに変換してフィルターを覗いてみたところ,12 月に咲いている地域がある.主に八重山諸島あたりの低緯度の地域が多そうだ.とはいえ,データ処理には関係ない.サクラの特性からして,月日のデータ長が 4 桁なら前年とみなして良さそうだ.
IF LEN(#MonthDay) = 4 THEN #Year = #Year - 1 ELSE #Year END IF…(1)
上記の仮想的なコードを組んでみる.「サクラに限れば」問題なさそうだ.しかし,秋の紅葉など他の生物の特性ではまた別のロジックが必要になることは言うまでもない.
DATE型のデータを組む
もっとも重要な年の判別ロジックができたら,後は文字列をつないで Date 型のデータを組む.
#Date = Datevalue(#Year & #Month & #Day)…(2)
#Month = LEFT(#MonthDay, 1)…(3)
#Month = LEFT(#MonthDay, 2)…(4)
#Day = Right(#MonthDay, 2)…(5)
日の値(#Day)は右から二桁取ってくるだけで良い.月の値(#Month)はデータ長により変わる.式 (1) に式 (2) を代入すると次の式 (6) となる.
IF LEN(#MonthDay) = 4 THEN #Date = Datevalue(#Year - 1 & #Month & #Day) ELSE #Date = Datevalue(#Year & #Month & #Day) END IF…(6)
こんなところだろうか.式 (6) に式 (3), (4), (5) を代入すると次の式 (7) となる.#MonthDay のデータ長が 3 か 4 かで月のデータ長を変えているところにも注目してほしい.
IF LEN(#MonthDay) = 4 THEN #Date = Datevalue(#Year - 1 & LEFT(#MonthDay & 2) & Right(#MonthDay, 2)) ELSE #Date = Datevalue(#Year & #Month = LEFT(#MonthDay, 1) & Right(#MonthDay, 2)) END IF…(7)
これが処理の中核となるコードだ.
実際には手動で…
と思ったのだが,いざ VBE を起動するとコードを書く気が失せた.若い頃はワークシート丸ごと変数に放り込んで2次元配列にしてちまちま取り出してたんだけどね.誰かできる人,お願い.
2列ずつ列を挿入しようとして選択してから右クリックしたら…
おい,複数列まとめて挿入できないじゃないか
全くなんて仕様だ.1列ずつちまちま挿入しろってか.もちっと融通きかせてもらえないものかな.ちなみにまとめて削除もできない仕様だ.クソだな.
LEN関数,LEFT関数,RIGHT関数,DATEVALUE関数を駆使する
ワークシート関数で日付に関連した関数はいくつかある.今回用いたのは4種類だ.月日のデータが3桁ないし4桁で記述されており,日は必ず2桁あることに注目した.右から2桁取れば残りは月のデータだけだ.まず,月を取り出そう.
=LEN(@MonthDay) - 2…(8)
月の桁数はこれでよい.次は月そのものの値を取り出す.
=LEFT(LEN(@MonthDay) - 2, 2)…(9)
日の値は右から2桁取り出したもの.
=RIGHT(@MonthDay, 2)…(10)
年はちょっと判別ロジックを組み込んだ式になる.
=IF(LEN(@MonthDay)=4, @Year - 1, @Year)…(11)
年,月,日の値をそれぞれ半角スラッシュで結んで結合する.(11), (9), (10) の順につなぐ.
=IF(LEN(@MonthDay)=4, @Year - 1, @Year)&"/"&LEFT(LEN(@MonthDay) - 2, 2)&"/"&RIGHT(@MonthDay, 2)…(12)
これだけではまだ日付として認識されていない.式 (12) を DATEVALUE 関数で囲んで初めて DATE 型のデータになる.
=DATEVALUE(IF(LEN(@MonthDay)=4, @Year - 1, @Year)&"/"&LEFT(LEN(@MonthDay) - 2, 2)&"/"&RIGHT(@MonthDay, 2))…(13)
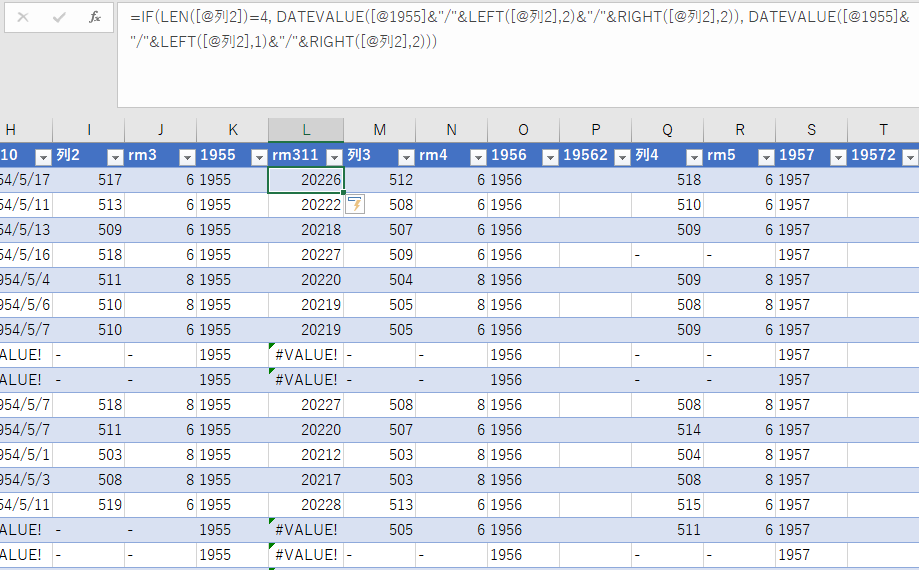
こんな感じになる.@ のついた変数はテーブルで列を表している.マイナスのついたセルを参照するとエラーが発生するが,後で消すから今はこのままにしておく.
最初は 5 桁の整数が表示されるが,慌てなくてよい.これはシリアル値といって,システム内部の数値であり,1900 年 1 月 1 日を起点として始まる年月日を表している.表示形式で日付型を指定してやればちゃんと見慣れた形式になる.
関数のネストは3層まで
関数がいくつも組み合わされると,めまいがしてくる人もいるだろう.慣れないうちは無理にネストするよりも一列ずつ参照セルを挿入し,順に隣のセルを参照したほうがよい.
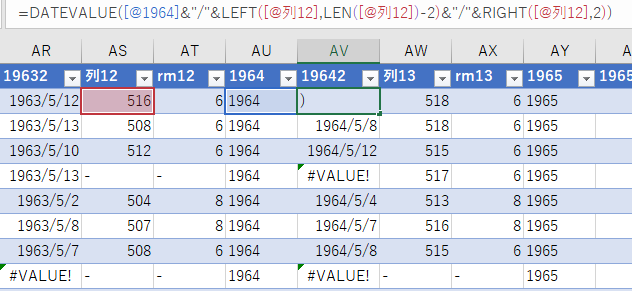
エラーが発生した時,修復に時間がかかるためだ.
中級者以上ならいくつかの関数を組み合わせることもできるようになっているはずだが,経験上 3 層以上のネストは後から理解するのが難しい.
引き継ぐ必要のあるワークシートなら,セル参照により隣の列を参照するようにしたほうがロジックの流れが明快になって分かりやすい.
同じ作業をひたすら繰り返す
地味な作業である.1953 年から 2018 年までの 65 回,同じ作業を繰り返す.こういうところこそ VBA に任せたいのだが,ワークシート関数で始めてしまったから続けるしかない.
官僚はこういう作業,得意なんだろうな.こういう作業が苦にならない自分も官僚向きなのかも知れないなどと要らぬことを考えながら作業を続ける.
最後は「値のみ貼り付け」
ひたすら辛い作業が終わったら,全体を選択して「コピー」「値のみ貼り付け」する.これでセル間の参照関係が解消され,自由に切り貼りの編集ができるようになる.
これをしないと,作業列を削除した途端に参照エラーが発生してパニックを起こすことになる.忘れないようにしよう.
4列ずつ下へ切り貼り
これも単純作業だ.先の図の第2階層を解きほぐす作業にあたる.
作業列の削除
年月日の列さえあれば後は不要だ.地点番号,地点名,rm, 年月日を残して他の列は削除しよう.テーブルのままだと複数の行はまとめて削除できるのに,列は同じことができない.不思議だ.テーブルをいったん「範囲に変換」すると複数列の削除ができるようになる.
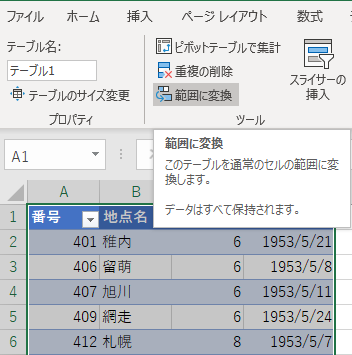
テーブル,再び
不要な列を削除したら,全領域をテーブルに変換する.
フィルターで不要な行を削除
フィルターをかけると不要な行がいっぱい出てくる.確認しつつ削除する.手動の作業のため地点名が抜けているところがあり,コピペで対応する.
平年値,最早値,最早年,最晩値,最晩年は別テーブルへ
ところで,テーブルの最後に余計なデータがある.これは集計関数による別のデータとみなすべきで,同じテーブルに格納すべきではない.ワークシートごと別のテーブルに分けるべきだ.
こういう余計な作業を強いるあたり,親切というべきか融通が効かないと言うべきか.
.txtファイルで保存
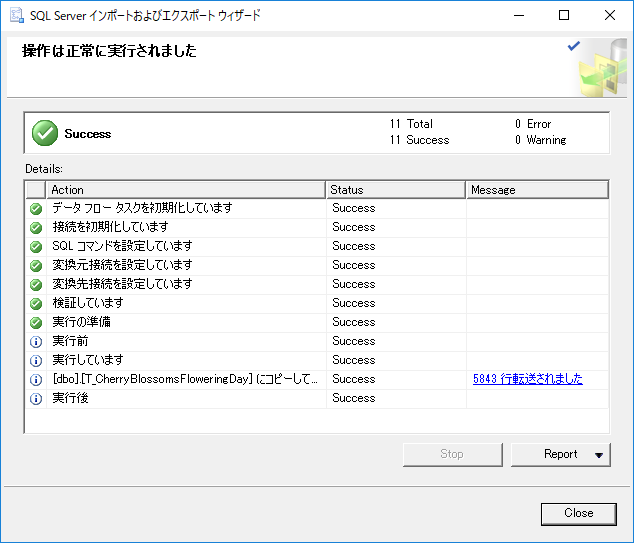
004ワークシートを .txt ファイルに保存する.これでデータベースにインポートできるようになった.
SQL Serverへのインポート
まとめ
気象庁の生物季節観測値には心底がっかりした
思いついてから丸三日かかって気象庁の PDF ファイルを第一正規形に変換した.比較的単純な作業の繰り返しだったが,最初から第一正規形で置いてあればこんな手間隙かけずに済んだのに.本当に残念だ.
官僚には猛省を促したい
本来なら即座にデータベースにインポートできる第一正規形で公開するのが筋だ.気象庁だけではない.霞ヶ関にはデータベースのことが分かっている人間がいないのか.ITだAIだ言う前に,あるだけで利用できないデータを何とかしてくれ.

“気象庁のサクラ開花日のテキストファイル” への2件の返信