
先日公開した記事トレーニングの最適化:安全な筋力トレーニングにおける新しい進展で参照していた引用元の論文からダウンロードできるファイルは PDF であるが,画像として保存されており,テキスト情報が抽出できなかった.以前ならスキャナから OCR ソフトで文字情報を抽出したが,最近だと Google ドキュメントが優秀なので,こちらを使ってテキスト情報を抽出してみた.
PDF ファイルを Google マイドライブにアップロードする
Google アカウントのマイドライブに,サイトからダウンロードした PDF ファイルをアップロードする.しばらくするとアイコンがファイルの 1 ページ目に変化する.
ファイルをGoogleドキュメントで開く
ファイルを右クリックするとメニューが現れるので,「アプリで開く」→「Google ドキュメント」を選択する.
こんな感じで開かれる.これは 1 ページ目の表紙みたいなもので,本文は 2 ページ目以降にある.
余計なスペースを削除する
画像は本文.誤字がほとんどないのは凄いとしか言いようがない.ただし,である.ところどころ,単語の中に余計なスペースが挿入されている.このスペース削除が意外と面倒だ.
これの削除は「検索と置換」が便利である.Windows なら Ctrl + H がショートカットキーだ.この作業はスマホでは難しい.
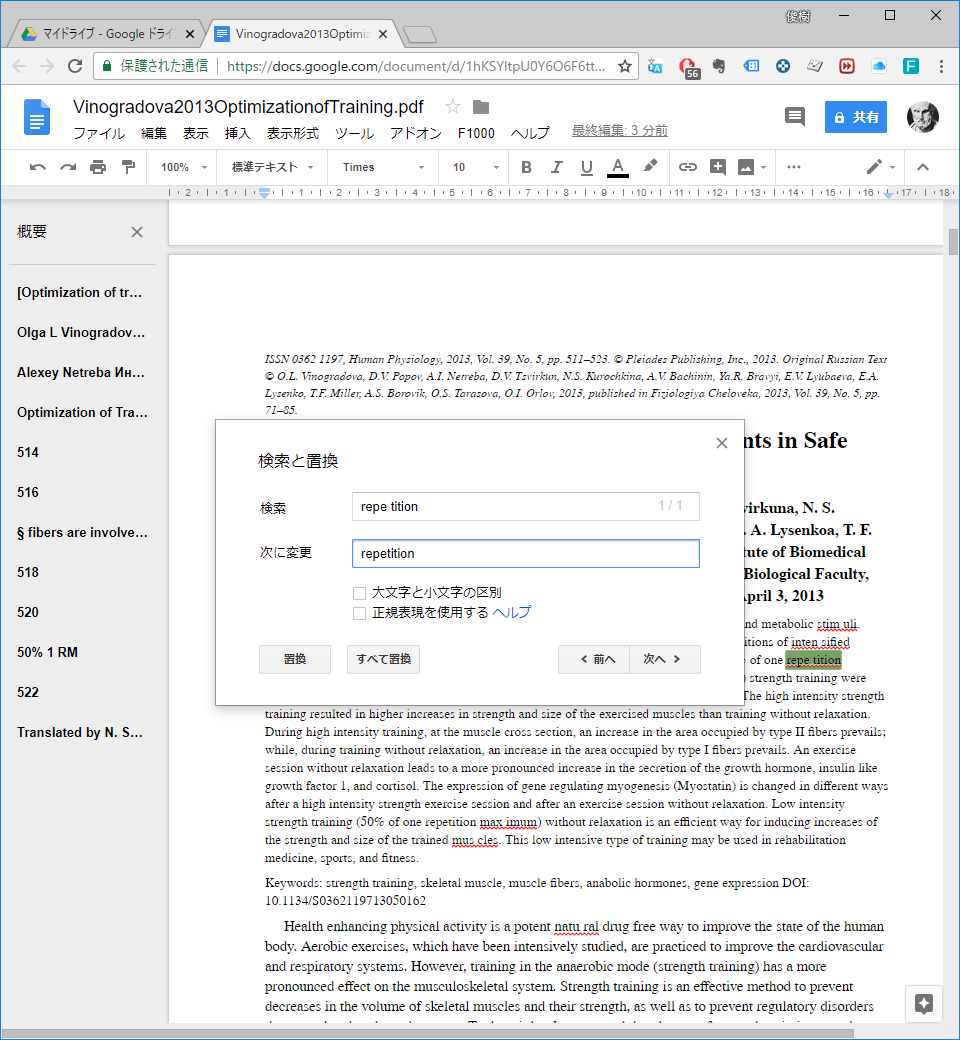
実はこの「検索と置換」が最も手間を要する.何より目視で探さないといけない.一応,あやしい単語は Google 側でハイライトしてくれるので,それを参考にしながらの作業となる.
どこまで置換するかはどこまでアウトプットするかによる.俺の場合は翻訳が主体なので,英文を読む時は PDF を紙に印刷してしまう.
図や表の周辺のテキストレイアウトは崩れる
これは Google ドキュメントの欠点の一つだ.見事にレイアウトが崩れる.英文をコピペしたい場合は注意が必要だ.一般的な書籍など,本文しかないのならほとんど問題はないだろうが,図や表,その説明文などが書いてある学術論文ではちょっと…というのが正直なところだ.
ところで,漫画の PDF を Google ドキュメントに食わせてみたら,どうなるのだろう?自炊代行が違法になる前に業者に頼んでスキャンしてもらったことがあるが,セリフの OCR が使い物にならなかった記憶がある.今ならどうなるのか,コンプライアンス上の懸念はあるが,単に技術的な疑問として書き残しておく.