

SQL Serverでサブクエリとウィンドウ関数のパフォーマンスを比較した.用いたデータベースはHeatStrokeDBで,熱中症の搬送人員と最高気温との相関関係を可視化し閾値をχ二乗検定するで作成したものである.
比較するツールはSET STATISTCS PROFILE ONコマンドである.クエリストアは筆者の環境では機能しなかった.
テーブル定義と要件
テーブル定義
テーブル定義は下記クエリのとおりである.
CREATE TABLE [dbo].[T_MaxTemperature]( [年月日] [date] NOT NULL, [都道府県コード] [int] NOT NULL, [都道府県] [nvarchar](10) NOT NULL, [日最高気温] [float] NOT NULL )
要件
今回の要件は「都道府県コードごとの日最高気温(県別最高気温)を抽出し,都道府県コード,年月日,県別最高気温をSELECTする」である.
サブクエリ
クエリ
DBCC DROPCLEANBUFFERS -- データバッファキャッシュのクリア DBCC FREEPROCCACHE -- メモリキャッシュのクリア SET STATISTICS PROFILE ON; SELECT M1.都道府県コード, M1.年月日, M1.日最高気温 FROM dbo.T_MaxTemperature AS M1 INNER JOIN (SELECT 都道府県コード, MAX(日最高気温) AS 県別最高気温 FROM dbo.T_MaxTemperature GROUP BY 都道府県コード) AS M2 ON M1.都道府県コード = M2.都道府県コード AND M1.日最高気温 = M2.県別最高気温 ORDER BY M1.都道府県コード; SET STATISTICS PROFILE OFF;
結果
| PhysicalOp | EstimateIO | EstimateCPU |
|---|---|---|
| NULL | NULL | NULL |
| Sort | 0.01126126 | 0.004350963 |
| Hash Match | 0 | 0.8054341 |
| Hash Match | 0 | 0.5808702 |
| Table Scan | 0.3579398 | 0.132498 |
| Table Scan | 0.3579398 | 0.132498 |
共通テーブル式
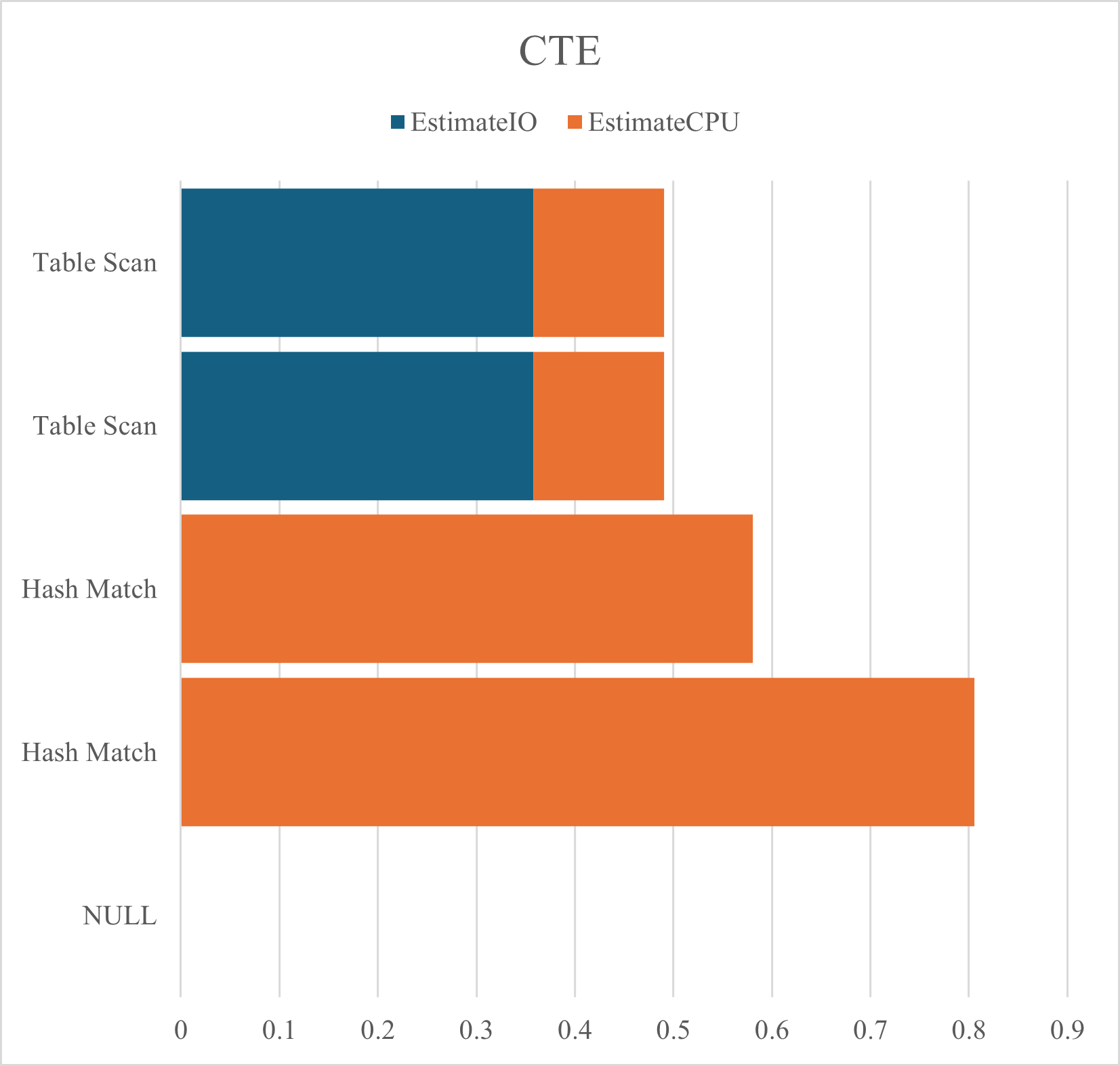
クエリ
DBCC DROPCLEANBUFFERS -- データバッファキャッシュのクリア DBCC FREEPROCCACHE -- メモリキャッシュのクリア SET STATISTICS PROFILE ON; WITH M1(都道府県コード, 県別最高気温) AS ( SELECT 都道府県コード, MAX(日最高気温) FROM dbo.T_MaxTemperature GROUP BY 都道府県コード ) SELECT M2.都道府県コード, M2.年月日, M2.日最高気温 FROM dbo.T_MaxTemperature AS M2 INNER JOIN M1 ON M2.都道府県コード = M1.都道府県コード AND M2.日最高気温 = M1.県別最高気温; SET STATISTICS PROFILE OFF;
結果
| PhysicalOp | EstimateIO | EstimateCPU |
|---|---|---|
| NULL | NULL | NULL |
| Hash Match | 0 | 0.8054341 |
| Hash Match | 0 | 0.5808702 |
| Table Scan | 0.3579398 | 0.132498 |
| Table Scan | 0.3579398 | 0.132498 |
ウィンドウ関数
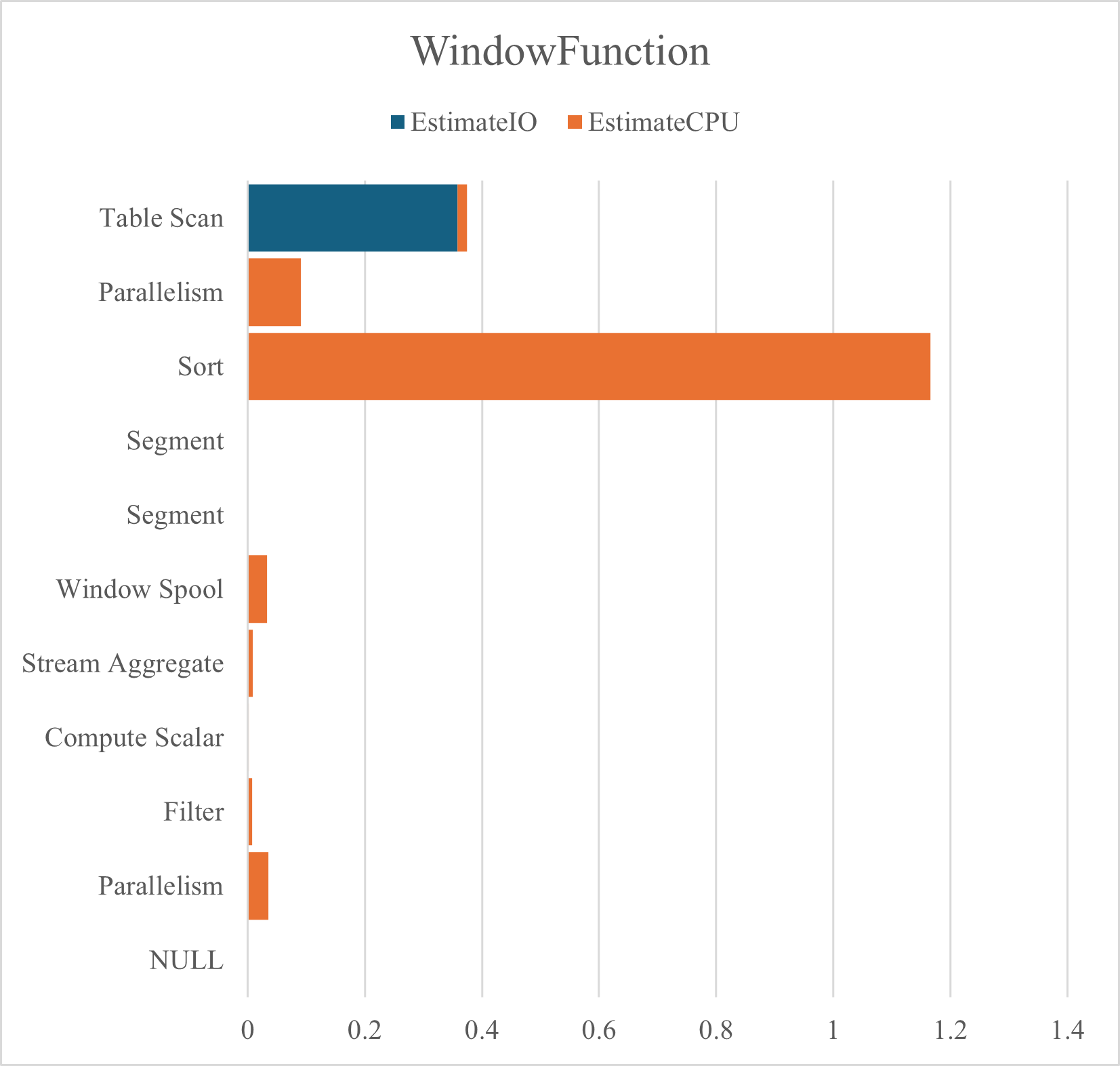
クエリ
DBCC DROPCLEANBUFFERS -- データバッファキャッシュのクリア DBCC FREEPROCCACHE -- メモリキャッシュのクリア SET STATISTICS PROFILE ON; SELECT * FROM (SELECT 都道府県コード, 日最高気温, 年月日, FIRST_VALUE(日最高気温) OVER(PARTITION BY 都道府県コード ORDER BY 日最高気温 DESC) AS 県別最高気温 FROM dbo.T_MaxTemperature) AS TMP WHERE 日最高気温 = 県別最高気温; SET STATISTICS PROFILE OFF;
結果
| PhysicalOp | EstimateIO | EstimateCPU |
|---|---|---|
| NULL | NULL | NULL |
| Parallelism | 0 | 0.03546821 |
| Filter | 0 | 0.0072186 |
| Compute Scalar | 0 | 0.001503875 |
| Stream Aggregate | 0 | 0.009444335 |
| Window Spool | 0 | 0.03305517 |
| Segment | 0 | 0 |
| Segment | 0 | 0.000944434 |
| Sort | 0.001407658 | 1.164954 |
| Parallelism | 0 | 0.09047845 |
| Table Scan | 0.3580183 | 0.01655244 |
結果の図示
サブクエリ,共通テーブル式,ウィンドウ関数のパフォーマンスを推定IO,推定CPUのグラフに示す.サブクエリと共通テーブル式は共にテーブルスキャンが2回発生していることがわかる.それに比べてウィンドウ関数ではソートの負荷が高いものの,テーブルスキャンが1回で済んでいることは特筆に値する.
使用したテーブルには約12万行のデータが存在しており,現状ではパフォーマンスにさほど差は見られない.しかし行数が増加するにつれてテーブルスキャンのコストは馬鹿にならなくなる.極力ウィンドウ関数を使用するに越したことはない.
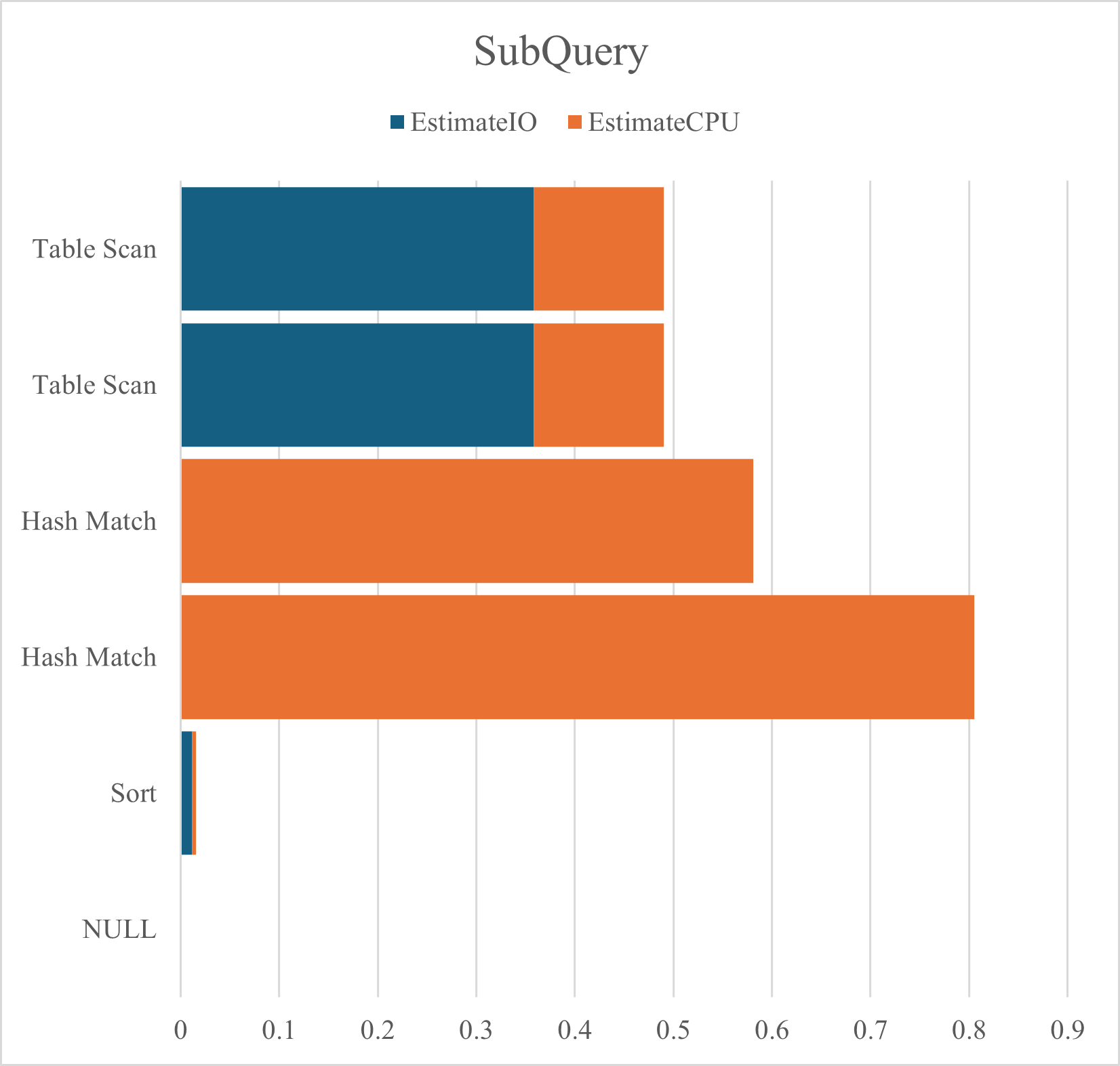
まとめ
サブクエリと共通テーブル式,ウィンドウ関数のパフォーマンスを比較した.12万行程度のデータではさほど差は見られなかったが,データの増加に従いウィンドウ関数のパフォーマンスが優れることはテーブルスキャンの回数が1回で済むことが示している.
このデータベースのテーブルには主キーを設定していないため,インデックスの恩恵を受けられていないという制約がある.主キーを設定した前後でもパフォーマンスを比較してみたいが,今後の課題である.