

データベースのテーブルに適切なインデックスを設定するのはクエリを高速化するうえで重要な施策である.今回,空間演算にコストがかかっていたクエリが空間インデックスの設定により高速化したので報告する.
地物の交差を計算するのは高コスト
使用するデータベースは国土数値情報の洪水浸水想定区域データをSQL Serverにアップロードし郵便番号から検索するで使用したZIPCODEDBである.郵便番号から小区域を特定し,交差する洪水浸水想定区域を表現するクエリは以下の通りである.
WITH CTE AS( SELECT Z.郵便番号 , Z.都道府県名 , Z.市区町村名 , Z.町域名 , C.S_NAME , C.geom FROM dbo.T_ZIPCODE AS Z INNER JOIN dbo.T_Small_Geographic_Area AS C ON Z.都道府県名=C.PREF_NAME AND Z.市区町村名=C.CITY_NAME AND C.S_NAME LIKE Z.町域名 +'%' AND Z.町域名 <>'' WHERE Z.郵便番号 = 1000001) SELECT dbo.T_MAX_RANGE.geom FROM CTE INNER JOIN dbo.T_MAX_RANGE ON CTE.geom.STIntersects(dbo.T_MAX_RANGE.geom) = 1 UNION ALL SELECT CC.geom FROM dbo.T_ZIPCODE AS ZZ INNER JOIN dbo.T_Small_Geographic_Area AS CC ON ZZ.都道府県名=CC.PREF_NAME AND ZZ.市区町村名=CC.CITY_NAME AND CC.S_NAME LIKE ZZ.町域名 +'%' AND ZZ.町域名 <>'' WHERE ZZ.郵便番号 = 1000001;
郵便番号1000001は皇居を示している.第14章 インデックス作成 (Beginning Spatial with SQL Server 2008)で示したように,空間演算は高コストである.
SET STATISTICS PROFILE ONにより統計情報を取得
下記クエリを10回実行して実行計画を取得する.SQL Serverはキャッシュを利用するため,キャッシュの影響を排除する必要がある.
DBCC DROPCLEANBUFFERS -- データバッファキャッシュのクリア DBCC FREEPROCCACHE -- メモリキャッシュのクリア SET STATISTICS PROFILE ON; WITH CTE AS( SELECT Z.郵便番号 , Z.都道府県名 , Z.市区町村名 , Z.町域名 , C.S_NAME , C.geom FROM dbo.T_ZIPCODE AS Z INNER JOIN dbo.T_Small_Geographic_Area AS C ON Z.都道府県名=C.PREF_NAME AND Z.市区町村名=C.CITY_NAME AND C.S_NAME LIKE Z.町域名 +'%' AND Z.町域名 <>'' WHERE Z.郵便番号 = 1000001) SELECT dbo.T_MAX_RANGE.geom FROM CTE INNER JOIN dbo.T_MAX_RANGE ON CTE.geom.STIntersects(dbo.T_MAX_RANGE.geom) = 1 UNION ALL SELECT CC.geom FROM dbo.T_ZIPCODE AS ZZ INNER JOIN dbo.T_Small_Geographic_Area AS CC ON ZZ.都道府県名=CC.PREF_NAME AND ZZ.市区町村名=CC.CITY_NAME AND CC.S_NAME LIKE ZZ.町域名 +'%' AND ZZ.町域名 <>'' WHERE ZZ.郵便番号 = 1000001; SET STATISTICS PROFILE OFF;
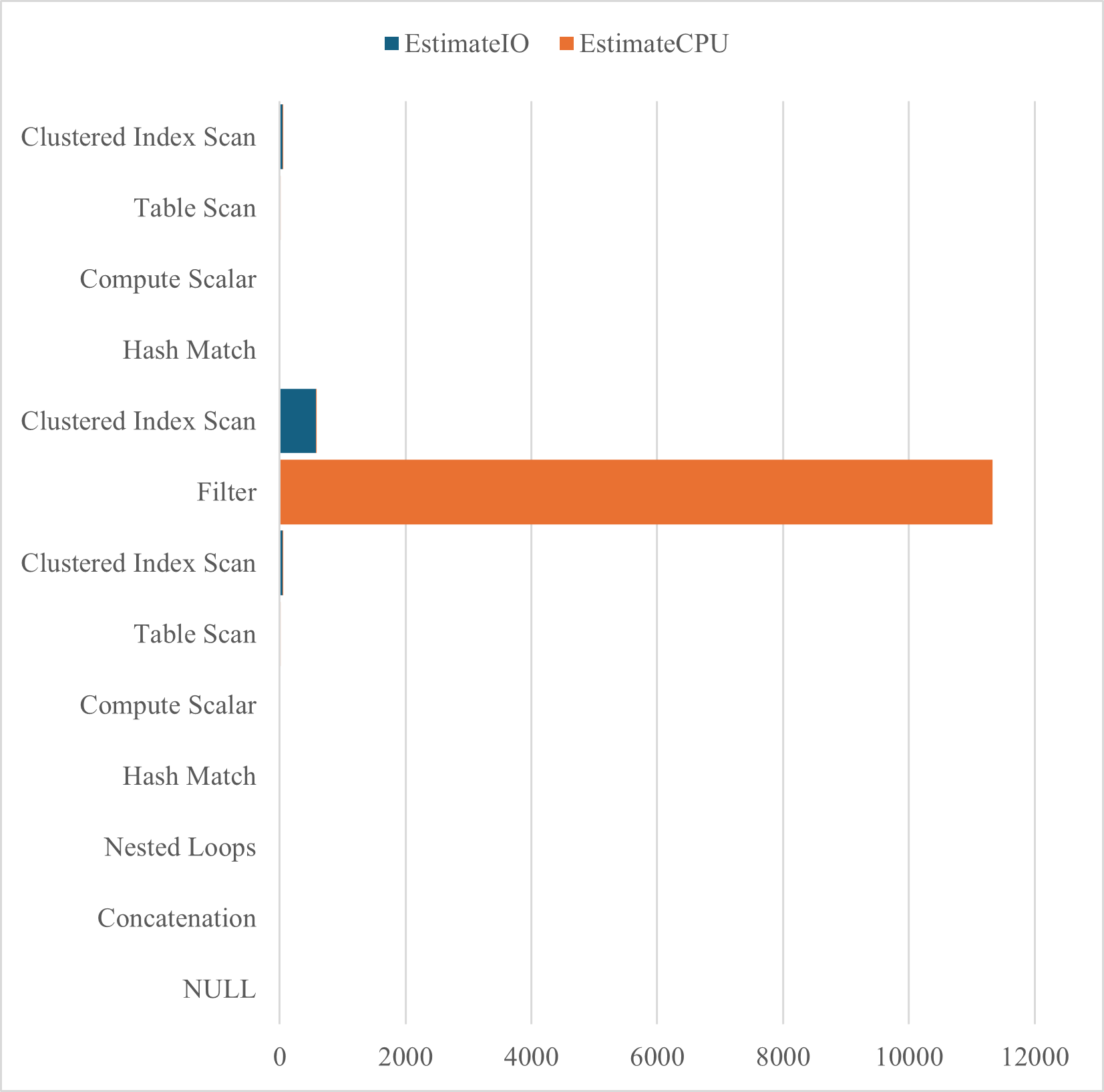
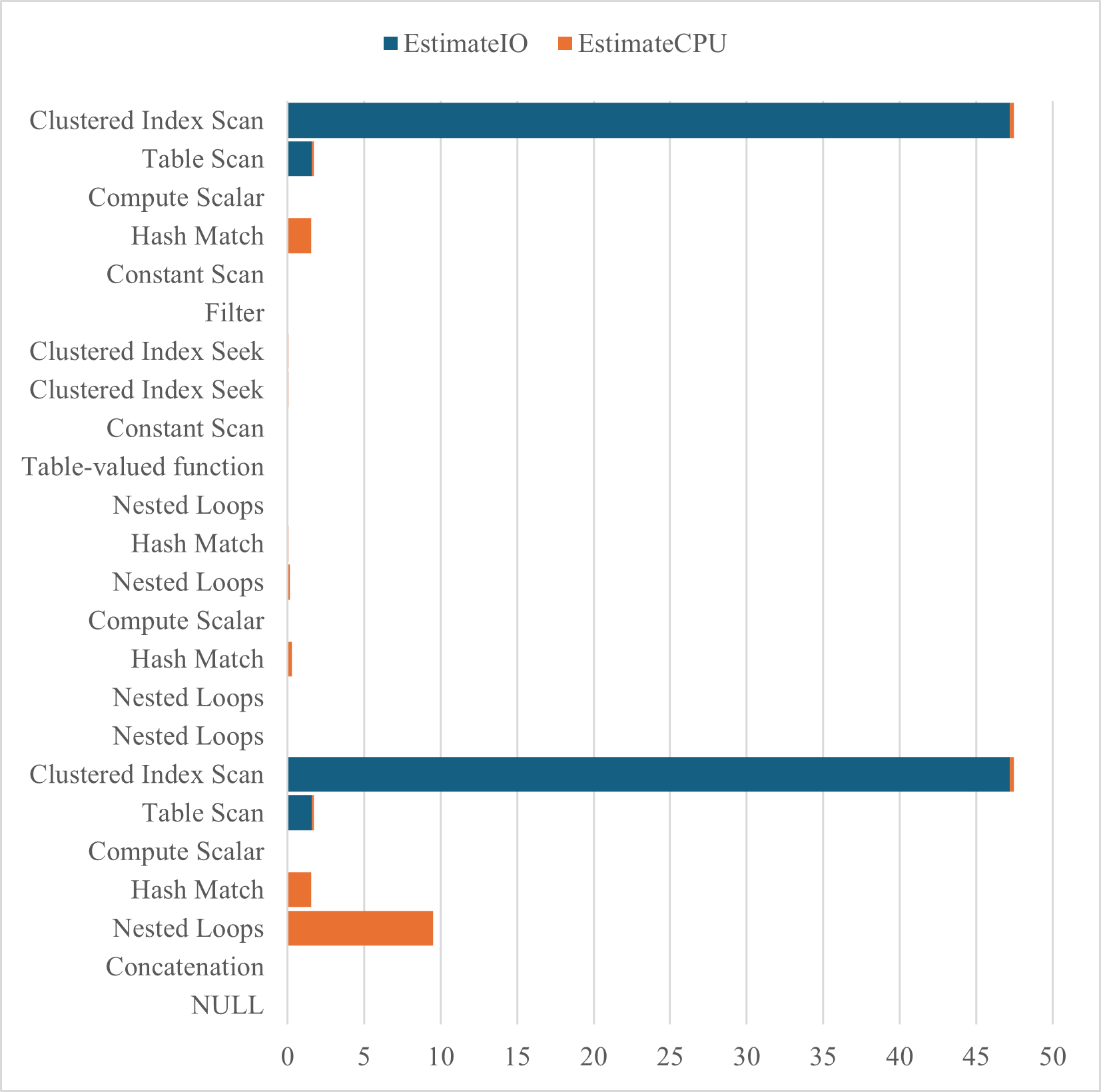
結果の概要を下図に示す.Filterにおけるインデックス作成前の推定CPUコストが極端に高く,これはSTIntersectsメソッドの空間演算が高コストであることを反映している.
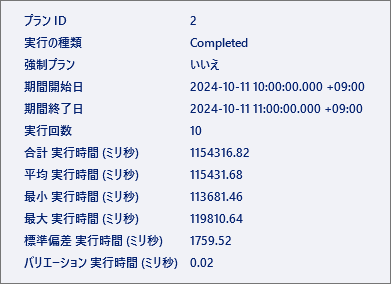
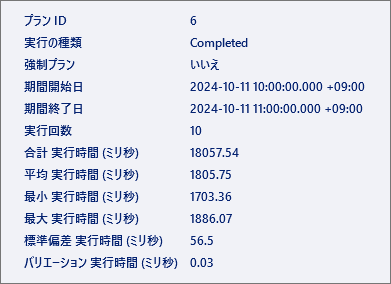
クエリストアで計測した実行時間は下図のとおりである.平均で2分近くかかっている.
空間インデックスの作成
今回空間インデックスを作成するテーブルは,洪水浸水想定区域を格納したT_MAX_RANGEテーブルと,小区域を格納したT_Small_Geographic_Areaテーブルである.
目的のテーブルのノードをクリックするとインデックスノードが出現するので,「インデックス」を右クリックして「新しいインデックス」「空間インデックス」と進む.
「追加」をクリックする.
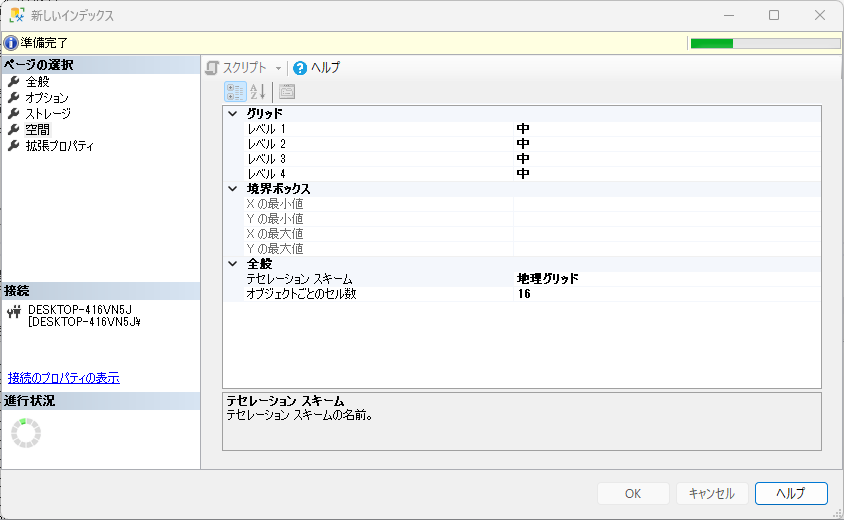
地物にチェックを入れる.データ型がgeography型であることに留意する.次の手順におけるテセレーションスキームと密接に関連しているからである.
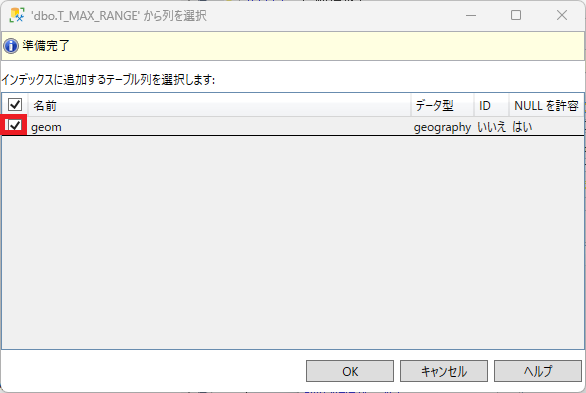
「列のデータ型とテセレーションスキームが一致しません」と警告が出ている.「ページの選択」で「空間」をクリック する.
「ページの選択」で「空間」をクリック
先の図で地物はgeography型であった.テセレーションスキームは規定でgeometry型なので型が一致しないとエラーが出ていたと思われる.翻訳間違いだと思うが,「地理グリッド」ではなく「ジオグラフィグリッド」が正しいと思われる.
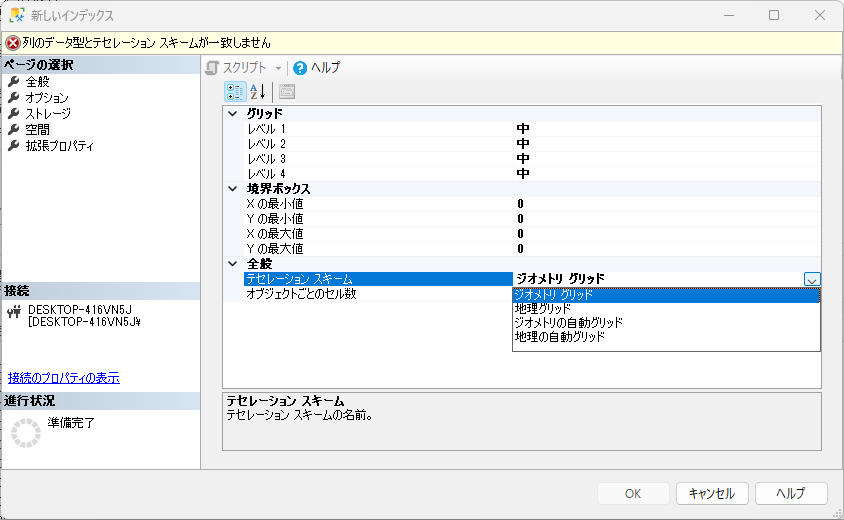
ここでは「地理グリッド」を選択する.グリッドにはレベル1からレベル4まであり,1レベルあたりのグリッド解像度はデフォルトの「中」だと8 × 8 グリッドに対応し,合計 64 個のセルを含むため,レベル4では644 個(約 1670 万)のセルを含んでいることになる.
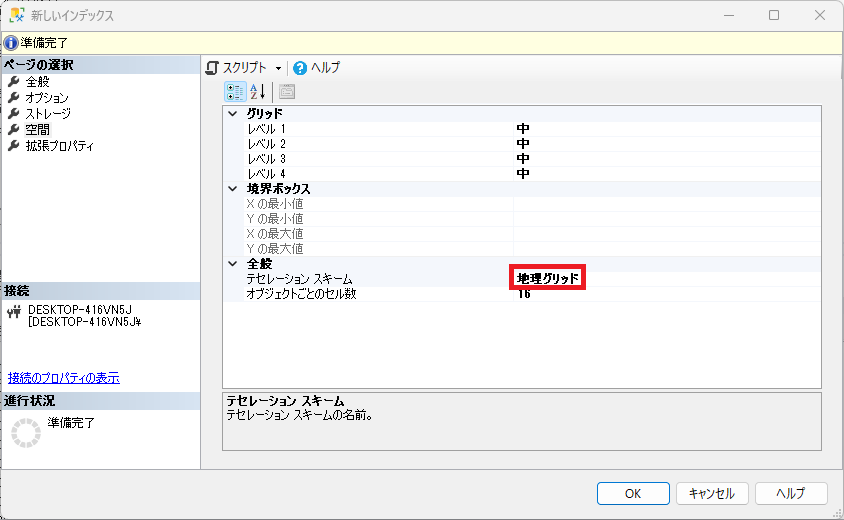
「OK」を選択するとインデックス作成が開始される.
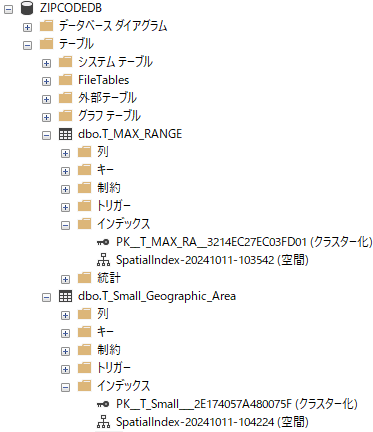
SQL Serverのオブジェクトエクスプローラで作成されたインデックスを確認する.
再度,SET STATISTICS PROFILE ONにて統計情報を取得
再度,インデックス作成前と同様のクエリを10回実行する.結果の概要を下図に示す.Filterのコストがほとんどかかっていない.
クエリストアで計測した実行時間は下図のとおりである.平均で1.8秒と2桁速くなっている.
結果の比較
下図のように,インデックスの効果は劇的であった.空間演算のコストが明らかに低下したため,オプティマイザの実行計画が変わっている.
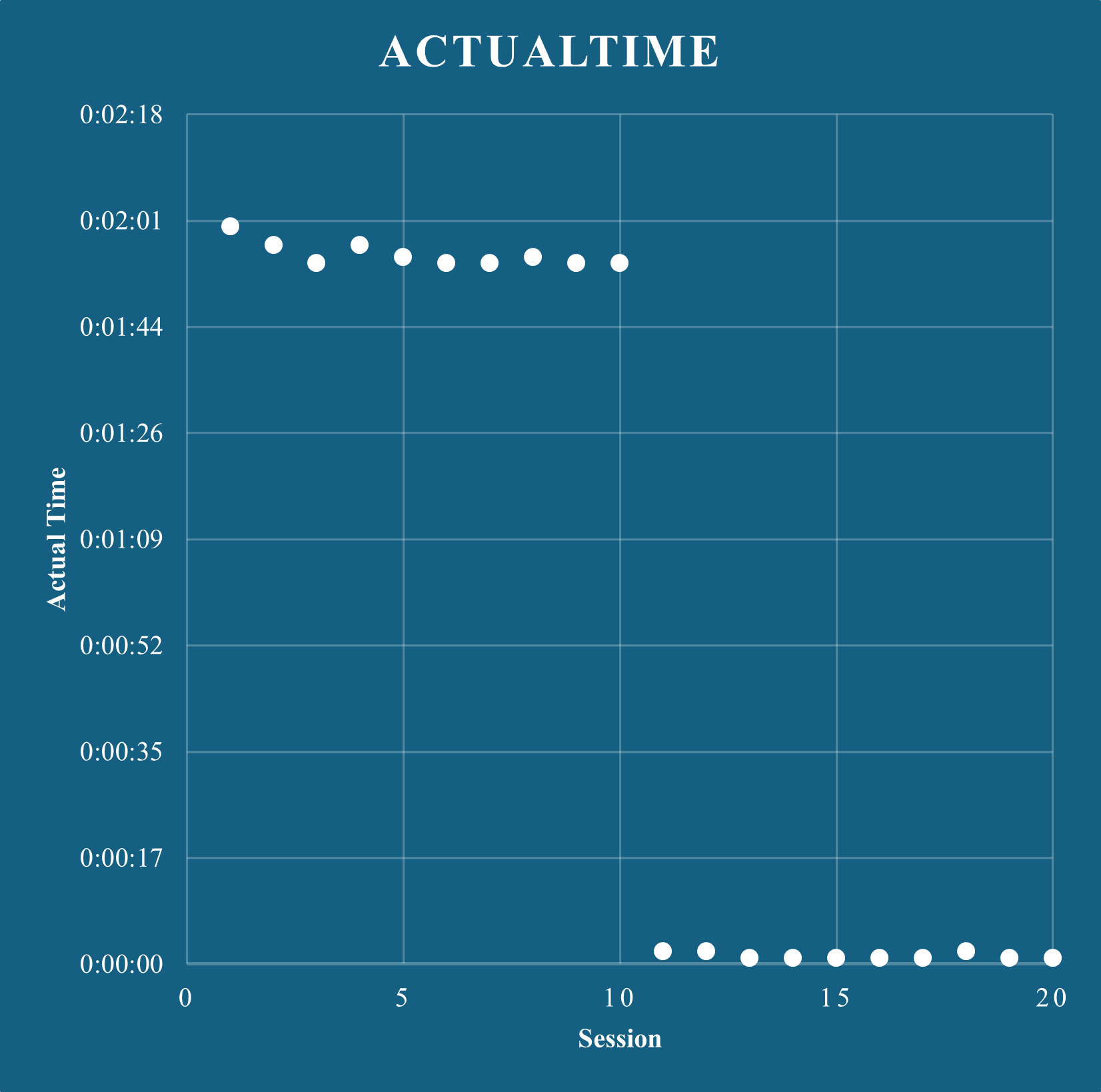
まとめ
地物を扱うデータベースにおいて,地物同士の空間演算は高コストであるため,適切な空間インデックスを作成することはクエリの高速化に有用であった.