

地球温暖化に伴い,台風の大型化や洪水被害の拡大が懸念されている.今回は国土交通省の公表している洪水浸水想定区域データを SQL Server にアップロードしたのでその経緯を報告する.
このデータは2022年9月時点で令和3年のものであり,毎年更新されていくものと思われる.関係各位はデータ更新が大変だろうが,頑張っていただきたい.
データ数 11,327,118 件をどう扱うか
全国を北海道から九州まで 9 つの地域に分割したものと,47都道府県に分割したものとがある.試しに QGIS で全データをマージしてみると,11327118 件であった.SQL Server でも荷が重い数だが,QGIS だとさらに重い.シェープファイルに保存する際にエラーが発生して2割ほどデータが削り落とされてしまった.
地域ごとにシェープファイルをマージすればよいのではと思いついた.
EPSG の違いに苦しむ
QGIS と違って SQL Server は異なる EPSG のデータを重ね合わせることができない.データベースにアップロードする際には元のデータの CRS を変更しておく必要がある.国土数値情報の EPSG は 6668 で,これは JGD2011 に該当する.しかし SQL Server の sys.spatial_reference_systems テーブルにはこの EPSG は存在せず,存在しない EPSG を指定して Shape2SQL からアップロードしようとしても,エラーで弾かれる.アップロードするまでに,シェープファイルの EPSG をアップロードしようとするデータベースのテーブルデータの EPSG にそろえておく必要がある.
QGIS でのベクタレイヤのマージの際に CRS を定義することで解決した.
データのダウンロード
元のデータは国土数値情報の洪水浸水想定区域データにある.北海道開発局,東北地方整備局,関東地方整備局,北陸地方整備局,中部地方整備局,近畿地方整備局,四国地方整備局,九州地方整備局からそれぞれシェープ形式をクリックしてダウンロードする.
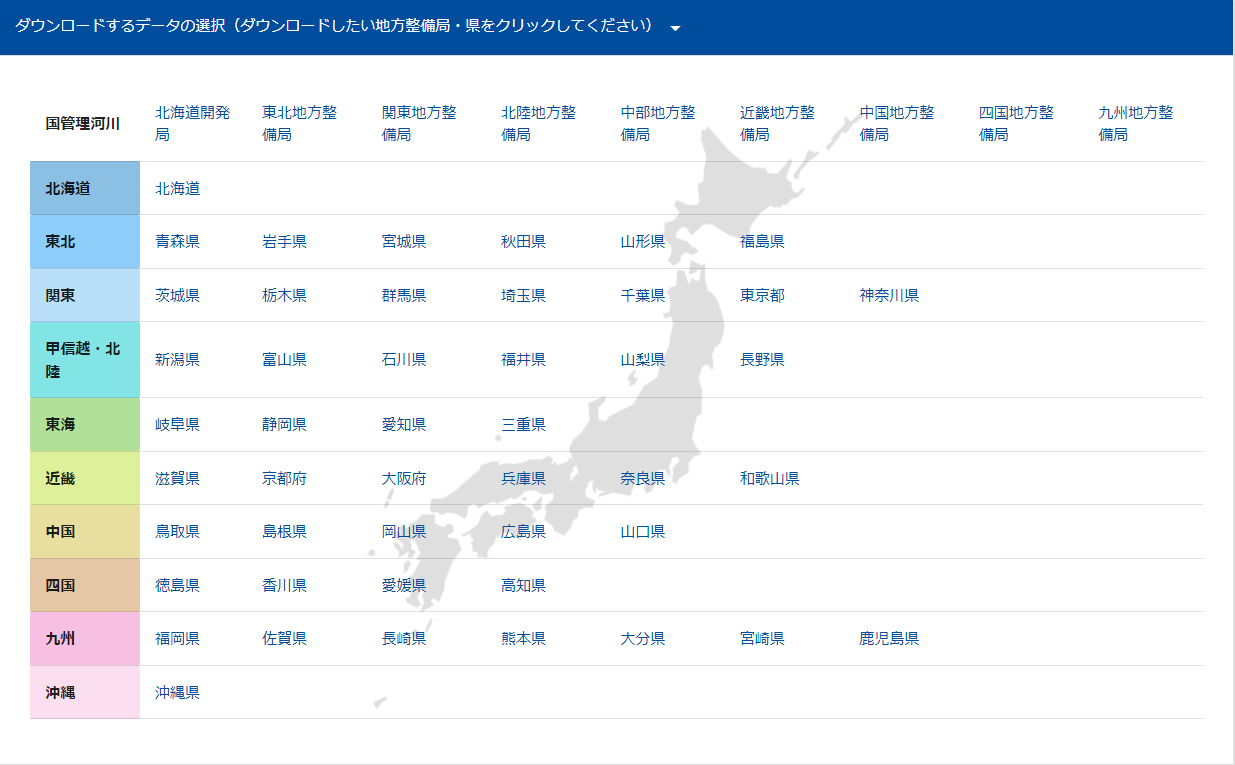
ダウンロードした zip ファイルを解凍すると4つのフォルダに分かれる.計画規模,想定最大規模,浸水継続時間,家屋倒壊等氾濫想定区域である.ここでは想定最大規模のデータを使うことにする.

QGIS にデータを読み込む
「レイヤ」「レイヤを追加」「ベクタレイヤを追加…」
「データソースマネージャ」の「ソース」で全シェープファイルを追加

ここで「追加」をクリックするとメインウィンドウにポリゴンが表示される.

「プロセシング」「ツールボックス」から「ベクタ一般」「ベクタレイヤをマージ」
「プロセシング」メニューから「ツールボックス」を選び,「ベクタ一般」から「ベクタレイヤをマージ」を選ぶ.
ベクタレイヤをマージの入力レイヤ
下図のように「ベクタレイヤをマージ」ダイアログボックスに遷移する.
「入力レイヤ」右側の「…」ボタンをクリックすると下図にように遷移する.「すべて選択」して左向きの三角形ボタンをクリックして先のダイアログに戻る.
「変換先の座標参照系」を変更する
入力レイヤの指定が終わったら,次は重要な座標参照系の変更である.「変換先の座標参照系」の右側にあるボタンをクリックする.「CRSの選択」で「カスタムCRS」を選択する.
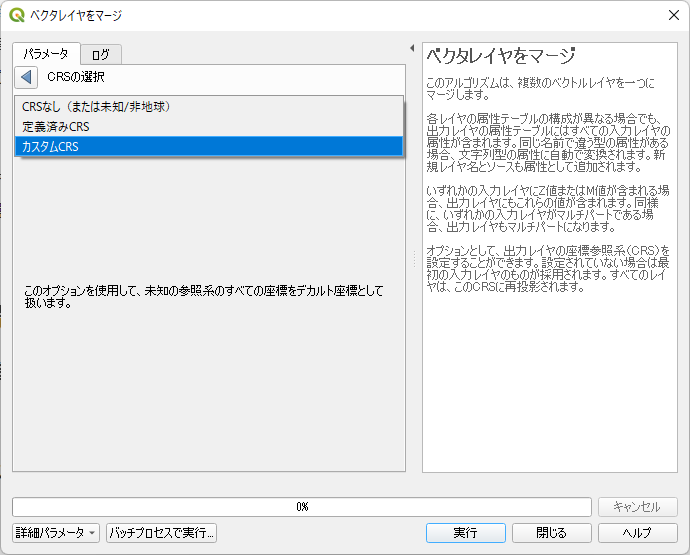
「フィルタ」にアップロード先のデータベースで定義した EPSG を入力
「フィルタ」にアップロード先のデータベースで定義している EPSG を入力する.ここでは 4612 としている.
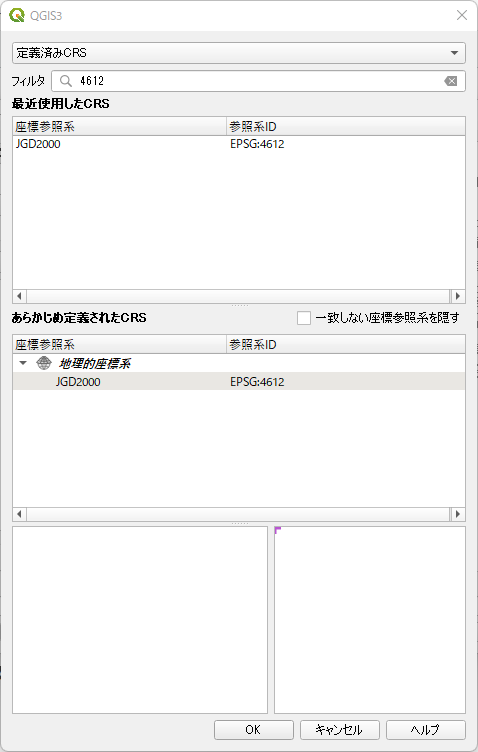
JGD2000 (EPSG: 4612) が選択できるのでクリックすると下図のようになるのでOKをクリックする.
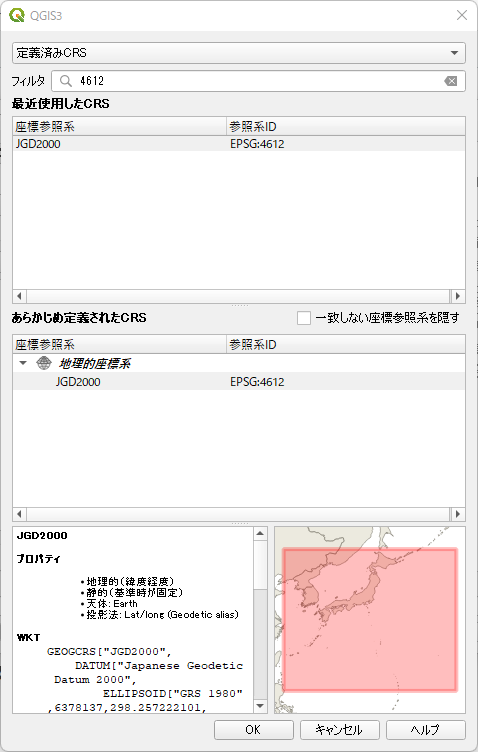
WKTで変換方法が記述されている.左向き三角形ボタンをクリックして最初のダイアログに戻る.
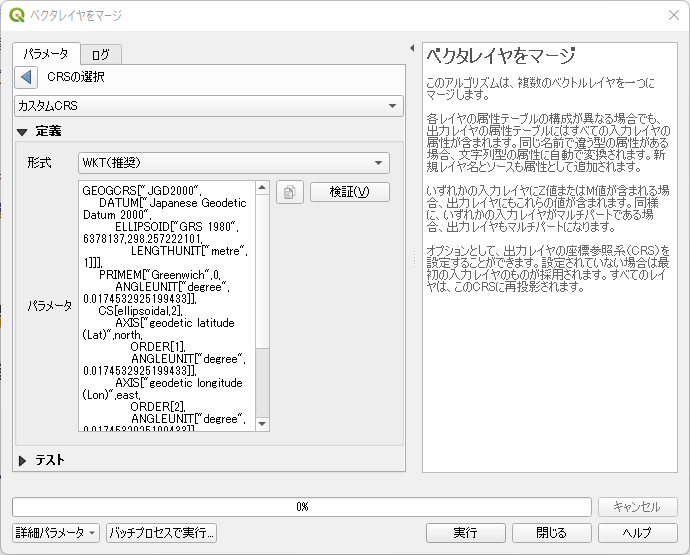
「実行」をクリック
入力レイヤと変換先の座標参照系の指定が終わった状態である.ここで「実行」をクリックする.
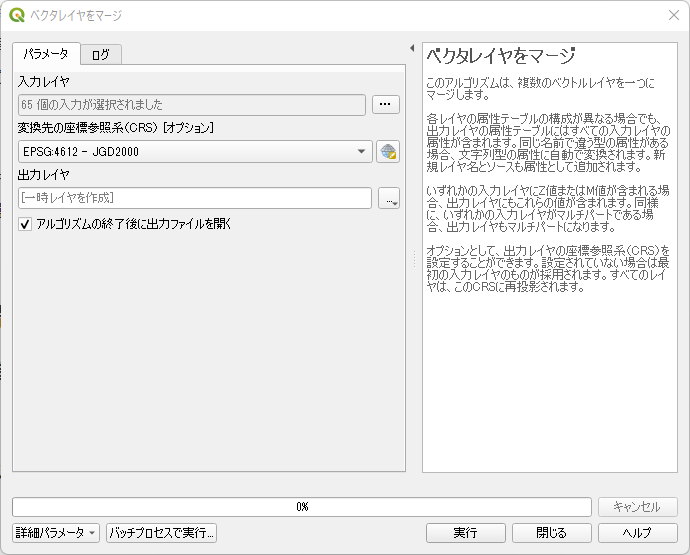
ベクタレイヤのマージが終了する.
出力レイヤを右クリックして「エクスポート」「新規ファイルに地物を保存」
マージされたベクタレイヤは「出力レイヤ」と言う名前でレイヤパネルに出現している.右クリックして「エクスポート」「新規ファイルに地物を保存…」を選ぶ.
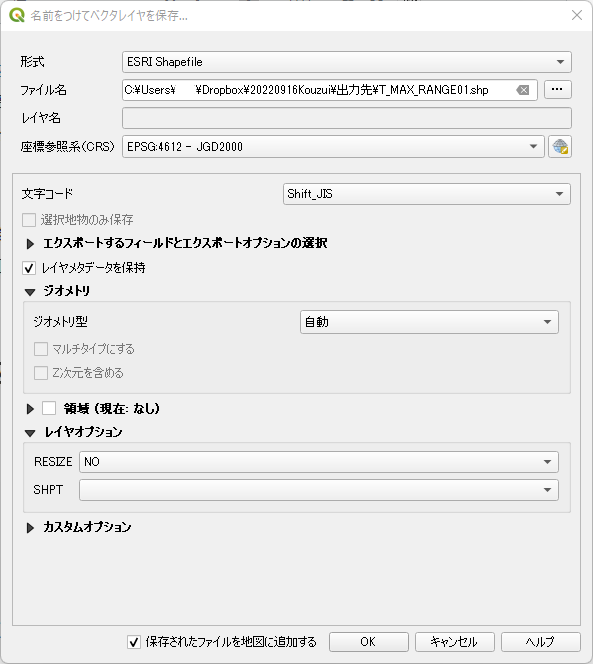
「ファイル名」右端のボタンをクリックしてフルパスのファイル名を指定する.ここでは T_MAX_RANGE01 というファイル名にしているが,これは連番にして後ほどの SQL Server での INSERT を楽にしようという魂胆である.
「名前をつけてベクタレイヤを保存」ダイアログの最終状態.OKをクリックして保存する.
上記の作業を地域の数だけ繰り返す.
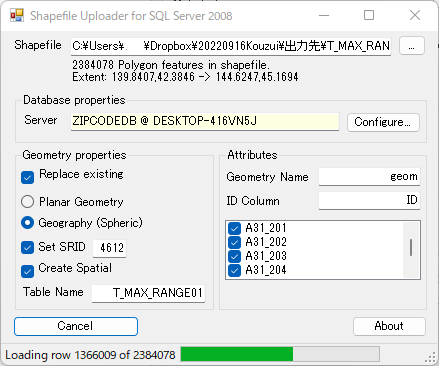
Shape2SQL で SQL Server にアップロード
これまでの作業で9地域のシェープファイルができているはずである.これらを Shape2SQL で SQL Server にアップロードする.アップロードにはかなりの時間を要する.
SQL Server でテーブルを作成
同じ構造を持つ空のテーブルを作成するには SQL Server Management Studio の機能を使う.作成した空のテーブルに元のテーブルからデータを INSERT し,元のテーブルを削除する.
「テーブルをスクリプト化」「新規作成」「新しいクエリエディターウィンドウ」
オブジェクトエクスプローラーで該当するデータベース,ここでは ZIPCODEDB だが,を右クリックして「テーブルをスクリプト化」「新規作成」「新しいクエリエディターウィンドウ」を選ぶ.
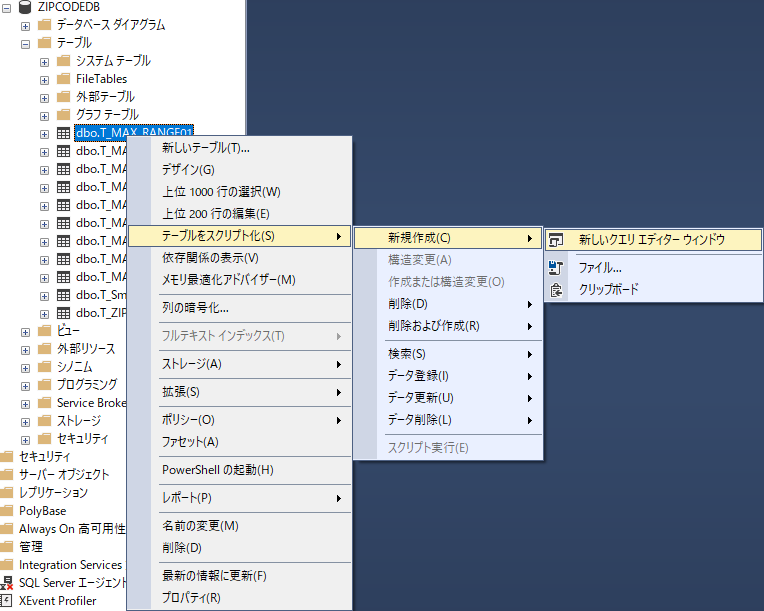
クエリエディターウィンドウにスプリクトが表示されるので,テーブル名を任意の名前に書き換える.今回は T_MAX_RANGE としている.制約名なども併せて変更しないとエラーが発生するので注意する.
USE [ZIPCODEDB] GO SET ANSI_NULLS ON GO SET QUOTED_IDENTIFIER ON GO CREATE TABLE [dbo].[T_MAX_RANGE]( [ID] [int] IDENTITY(1,1) NOT NULL, [A31_201] [bigint] NULL, [A31_202] [nvarchar](255) NULL, [A31_203] [nvarchar](255) NULL, [A31_204] [nvarchar](255) NULL, [layer] [nvarchar](255) NULL, [path] [nvarchar](255) NULL, [geom] [geography] NULL, PRIMARY KEY CLUSTERED ( [ID] ASC )WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON, OPTIMIZE_FOR_SEQUENTIAL_KEY = OFF) ON [PRIMARY] ) ON [PRIMARY] TEXTIMAGE_ON [PRIMARY] GO ALTER TABLE [dbo].[T_MAX_RANGE] WITH CHECK ADD CONSTRAINT [enforce_srid_geometry_T_MAX_RANGE] CHECK (([geom].[STSrid]=(4612))) GO ALTER TABLE [dbo].[T_MAX_RANGE] CHECK CONSTRAINT [enforce_srid_geometry_T_MAX_RANGE] GO
INSERT INTO…SELECT でデータを一括挿入
下記のクエリを実行してデータを新しいテーブル T_MAX_RANGE に挿入する.連番を 01 から 09 までインクリメントしていく.ID 列は自動採番のため外しておく.
USE ZIPCODEDB; GO INSERT INTO dbo.T_MAX_RANGE ( A31_201 , A31_202 , A31_203 , A31_204 , layer , path , geom ) SELECT A31_201 , A31_202 , A31_203 , A31_204 , layer , path , geom FROM dbo.T_MAX_RANGE01
元のテーブルを削除
下記のクエリを実行してもはや不要となったテーブルを削除する.
USE ZIPCODEDB; GO DROP TABLE dbo.T_MAX_RANGE01 DROP TABLE dbo.T_MAX_RANGE02 DROP TABLE dbo.T_MAX_RANGE03 DROP TABLE dbo.T_MAX_RANGE04 DROP TABLE dbo.T_MAX_RANGE05 DROP TABLE dbo.T_MAX_RANGE06 DROP TABLE dbo.T_MAX_RANGE07 DROP TABLE dbo.T_MAX_RANGE08 DROP TABLE dbo.T_MAX_RANGE09
結果
合計は 11,327,118 件である.
| 地域 | 件数 |
|---|---|
| 北海道開発局 | 2,384,078 |
| 東北地方整備局 | 704,021 |
| 関東地方整備局 | 2,606,295 |
| 北陸地方整備局 | 1,001,058 |
| 中部地方整備局 | 1,154,055 |
| 近畿地方整備局 | 490,023 |
| 中国地方整備局 | 584,920 |
| 四国地方整備局 | 1,596,015 |
| 九州地方整備局 | 806,653 |
属性テーブルのダメなところ
2022年9月時点では,洪水浸水想定区域データは実用に耐えない.
値がほぼ NULL
SQL Server で確認したところ,次の特徴が認められた.
- 「河川番号」 A31_201 が 1 から 6 のダミー値で埋められている.
- 「河川名」 A31-202 に日付が入力されている行がある.
- その他の列「河川管理番号」 A31-203 および「河川管理者」 A31_204 は恐らくすべて NULL である.
これは頂けない.シェープファイルが河川名ごとに分類できているのだから,河川番号は入力可能なはずである.データベースで河川名や水域名で検索し,洪水の想定範囲を図示するという用途に使いたいのに,これでは台無しである.国土交通省には改善を強く要望したい.
8 列あるはずの属性が 4 列しかない
SQL Server にアップロードしてから気がついたのだが,属性テーブルは A31_201 から A31_208 まで8列あるはずなのだが,実際には A31-204 までの 4 列しかない.ダウンロードしたてのシェープファイルを確認してみたが,同じである.想定最大規模だけでなく,計画規模,浸水継続時間および家屋倒壊等氾濫想定区域も同様であった.国土交通省の更新作業が追いついていないのであろうか?これも要改善である.想定最大規模で欠損している列は以下の通り.
- A31_205 浸水深ランク
- A31_206 指定年月日
- A31_207 告示番号
- A31_208 指定の前提となる降雨
憶測
浸水深ランクコードを見ていて気がついたのだが,A31_201 に入っている 1 から 6 の数値は,浸水深ランクなのかもしれない.また A31_202 に入っている日付は,本来 A31_206 の指定年月日なのかもしれない.
だとしても筋が悪い.本来あるべきデータがなく,別の列のデータが紛れ込んでいるとなると,データベース以前の問題である.
コード例
下記クエリを実行してみる.指定した郵便番号の小地域が,洪水浸水想定区域データと重なっているかを調べるクエリである.結果の解釈には注意が必要で,1 行であれば洪水浸水想定区域データと重なっていないが,2 行以上であっても重なっているとは限らない.
STIntersects() メソッドは空間インデックスを使用してもなお,計算コストが非常に高い.クエリの実行には 1 分 30 秒ほどかかり,結果が 1 行だと 10 分以上かかった.STIntersects() メソッドの代わりに Filter() メソッドを使ってみたが,若干速くなる程度で,著明な改善は認められなかった.
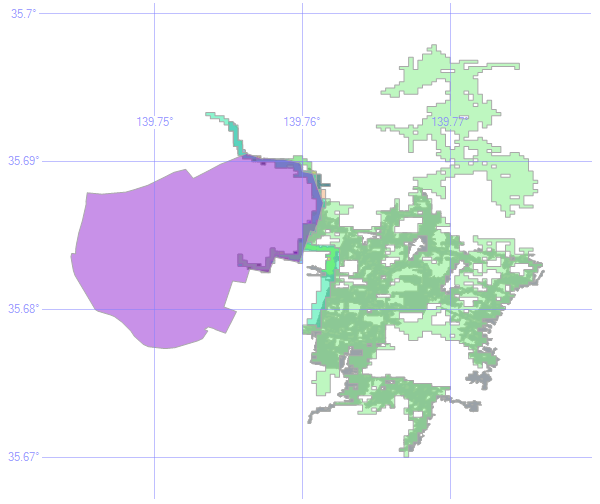
コード例は郵便番号に 1000001 を指定している.これは皇居を示し,下図では紫色のポリゴンで表示されている.一方,緑系のポリゴンで表示されている洪水浸水想定区域は皇居の東側に集中していることが分かる.
USE ZIPCODEDB; GO WITH CTE AS( SELECT Z.郵便番号 , Z.都道府県名 , Z.市区町村名 , Z.町域名 , C.S_NAME , C.geom FROM dbo.T_ZIPCODE AS Z INNER JOIN dbo.T_Small_Geographic_Area AS C ON Z.都道府県名=C.PREF_NAME AND Z.市区町村名=C.CITY_NAME AND C.S_NAME LIKE Z.町域名 +'%' AND Z.町域名 <>'' WHERE Z.郵便番号 = 1000001) SELECT dbo.T_MAX_RANGE.geom FROM CTE INNER JOIN dbo.T_MAX_RANGE ON CTE.geom.STIntersects(dbo.T_MAX_RANGE.geom) = 1 UNION ALL SELECT CC.geom FROM dbo.T_ZIPCODE AS ZZ INNER JOIN dbo.T_Small_Geographic_Area AS CC ON ZZ.都道府県名=CC.PREF_NAME AND ZZ.市区町村名=CC.CITY_NAME AND CC.S_NAME LIKE ZZ.町域名 +'%' AND ZZ.町域名 <>'' WHERE ZZ.郵便番号 = 1000001
(167 行処理されました)
コード例では郵便番号から洪水浸水想定区域を抽出したが,逆に洪水浸水想定区域から該当する郵便番号や小地域を抽出するクエリも考えられる.不動産業界にとっては隠しておきたいデータであろうが,防災の観点からは今後どうしても必要なデータである.機会があれば試みたい.
まとめ
国土交通省の洪水浸水想定区域データをダウンロードし,QGIS で加工して SQL Server にアップロードした.
属性データには欠損している列があり,テーブルが公表通りの構造になっていない.また格納されているデータにも不具合が多数認められる.
以上の理由から,2022年9月時点では洪水浸水想定区域データは実用に耐えない.
コード例では郵便番号から小地域を抽出し,交差する洪水浸水想定区域を重ねて抽出した.
メタデータ
河川番号とは河川コードのことである.河川管理者番号と河川管理番号はおそらく同じものであり,作成種別コードを指している.浸水深ランクは浸水深ランクコードを指している.浸水継続時間ランクは浸水継続時間ランクコードを指している.危険区域区分は危険区域区分コードを指している.
| 計画規模 | 想定最大規模 | 浸水継続時間 | 家屋倒壊氾濫 |
|---|---|---|---|
| 河川番号 | 河川番号 | 河川番号 | 河川番号 |
| 河川名 | 河川名 | 河川名 | 河川名 |
| 河川管理者番号 | 河川管理番号 | 河川管理番号 | 河川管理番号 |
| 河川管理者 | 河川管理者 | 河川管理者 | 河川管理者 |
| 浸水深ランク | 浸水深ランク | 浸水継続時間ランク | 危険区域区分 |
| 指定年月日 | 指定年月日 | 指定年月日 | 指定年月日 |
| 告示番号 | 告示番号 | 告示番号 | 告示番号 |
| 指定の前提となる降雨 | 指定の前提となる降雨 | 指定の前提となる降雨 | 指定の前提となる降雨 |
2023年3月29日時点で下記のようにコメントした.
(6)新たに整備を希望されるデータ、データ内の項目があればご記入ください。
北海道開発局のデータには想定最大規模しかデータがありません(家屋倒壊等氾濫想定区域・浸水継続時間・計画規模がない).
東北地方整備局には計画規模と想定最大規模のデータしかありません(浸水継続時間・家屋倒壊等氾濫想定区域がない).
関東地方整備局には家屋倒壊等氾濫想定区域がありません.
北陸地方整備局には計画規模と浸水継続時間のデータしかありません(想定最大規模と家屋倒壊等氾濫想定区域がない).
近畿地方整備局には想定最大規模と計画規模のデータしかありません(浸水継続時間と家屋倒壊等氾濫想定区域がない).
四国地方整備局と九州地方整備局にはファイルの欠損はありませんが令和3年のデータがありません.
半年前に改善を申し入れた時点ではこうしたファイルの欠損はなかったと存じます.検討中なのでしょうか?ぜひすべてのデータを公開していただきたく存じます.
なお,属性テーブルの構造については8列に改善され,データ構造も整備していただいたようで,感謝申し上げます.
(7)ダウンロードシステムに希望する機能があればご記入ください。
都道府県ごとのデータをダウンロードしてみましたが,殆どのzipファイルが空で解凍できませんでした.一時的な障害かもしれませんが,ファイルの精査をお願いします.
(9) 自由記入欄(ご感想、お気づきの点、本サイトにぴったりな愛称など。)
オラクルやマイクロソフトなど,主要なデータベースベンダーに最新のEPSGに対応するよう働きかけてください.