世界各国の人口推移およびGDP推移を取得したい.そんな場合は国連や世界銀行のデータを活用する.今回は国連から人口推移,世界銀行からGDP推移のデータをそれぞれ取得したので経緯を紹介する.
国連の人口データおよび世界銀行のGDPデータをダウンロードする

Co-evolution of human and technology
世界各国の人口推移およびGDP推移を取得したい.そんな場合は国連や世界銀行のデータを活用する.今回は国連から人口推移,世界銀行からGDP推移のデータをそれぞれ取得したので経緯を紹介する.
気象庁の過去の気象データ・ダウンロードからは膨大な気象データをダウンロードできる.今回の記事ではSQL Server内に構築した熱中症データベースに日平均風速のテーブルを追加する.
我々の手元にあるスマホにはかなり高性能な衛星測位システムが備わっている.GPS, GLONASS, QZSS, Galileo など.それぞれ米国,ロシア,日本,EU が管理するものである.これらのシステムを利用したアプリにルートヒストリーというものがあり,移動経路をログとして記録できる.今回はこのアプリから取得したファイルをQGISでシェープファイルに変換し,SQL Serverにアップロードするまでを記事とした.
“iOSのルートヒストリーから取得したGPXファイルをQGISでシェープファイルに変換しSQL Serverにアップロードする” の続きを読む

前回の記事(国土数値情報の令和2年の医療圏データの文字化けが直っていた)では国土数値情報の医療圏データで四苦八苦した様子を掲載した.今回は二次医療圏テーブルの文字化けの解決を試みる.
以前の投稿(Shape2SQL でシェープファイルを SQL Server 2008 R2 にアップロードする)で国土数値情報ダウンロードサービスの医療圏データが文字化けしていると記述した.改めてダウンロードして SQL Server にアップロードしたところ,いつの間にか文字化けが直っていた.以前にも河川データの文字化けを指摘したことがあるが,こちらも修正されていた(国土数値情報の河川データが一部直っていた件).どうやら国土交通省に指摘すると修正してくれるらしい.
本書のこの部では,geography 型および geometry 型でデータをフィルターし解析できるメソッドを論ずる.それはアプリケーションにおいて空間データの力を開発するのに使うのに必要な主要な機能を提供してくれる.
そのメソッドは3つのカテゴリに分類される.章ごとに一つ.第11章では個別の空間オブジェクトのプロパティについての情報を解析して返すメソッドを扱う.第12章では既存のオブジェクト間の組み合わせまたは修飾の間の新しいオブジェクトを定義するメソッドをカバーする.第13章ではオブジェクト間の関係をテストするメソッドを紹介する.例えば同一性,近接性,交差などである.
“第 11 章 空間オブジェクトのプロパティを検査する(Begining Spatial with SQL Server 2008)” の続きを読む
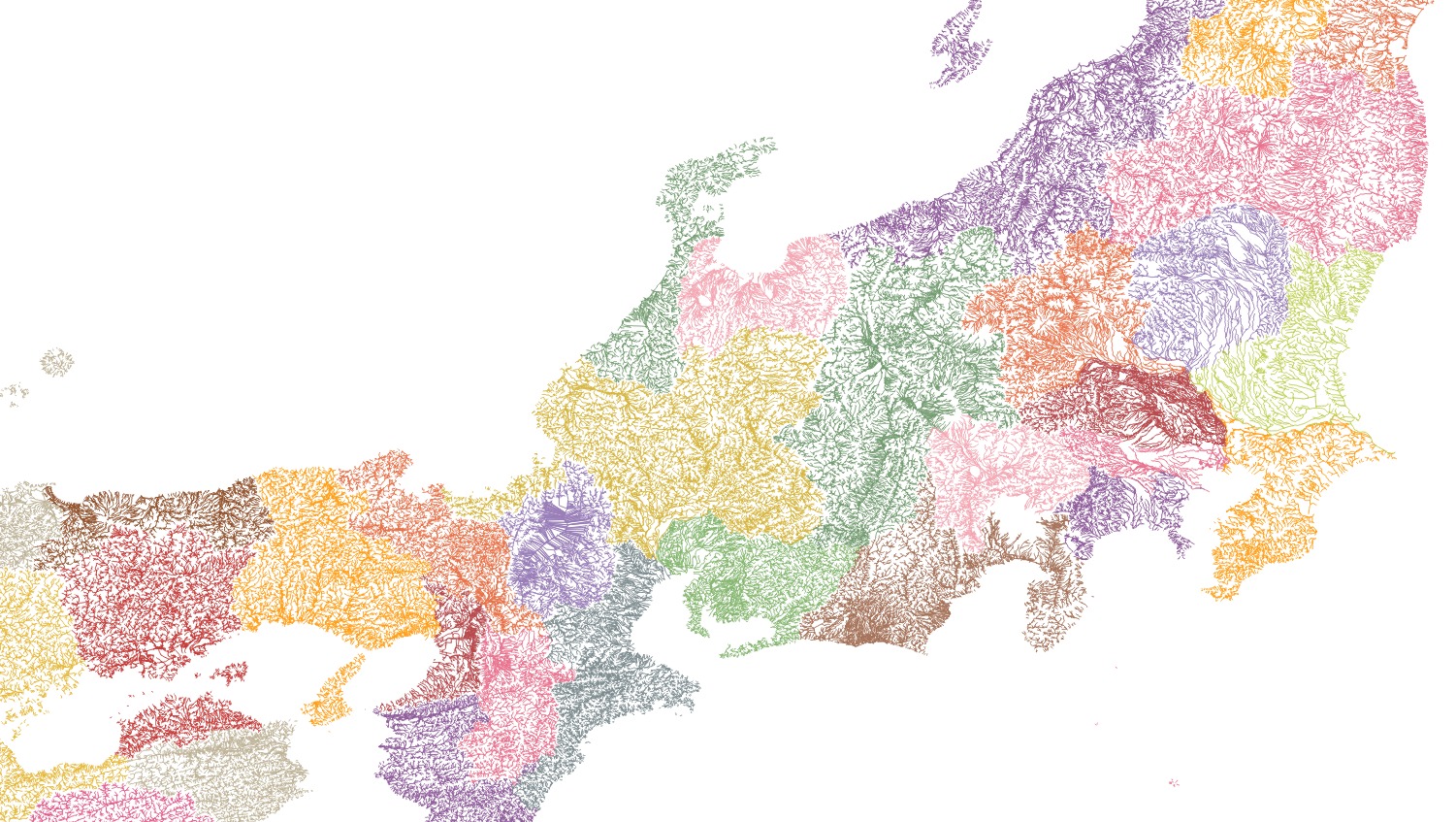
国土数値情報の河川データは都道府県ごとに分かれており,一つのシェープファイルに結合したかった.調べてみると QGIS でできそうだったので実行してみた.
前章では,空間参照系の背後にある理論を紹介し,異なる種類のシステムが地球上の特徴を記述する方法を説明した.本章では,これらのシステムを適用して SQL Server 2008 における新しい空間データ型を使って空間情報を蓄積する方法を学んでもらう.
“第 2 章 SQL Server 2008 で空間データを実装する (Beginning Spatial with SQL Server 2008)” の続きを読む
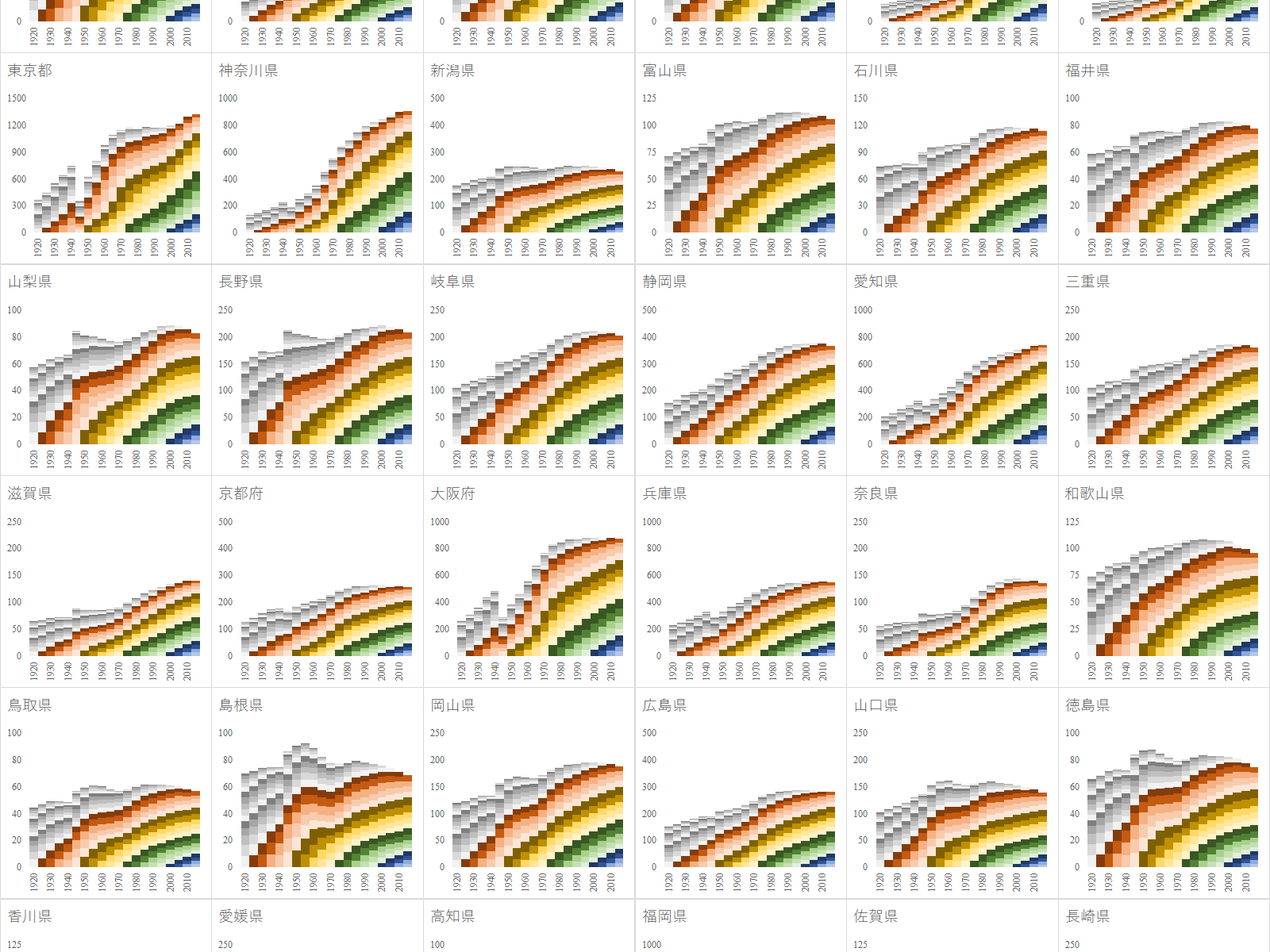
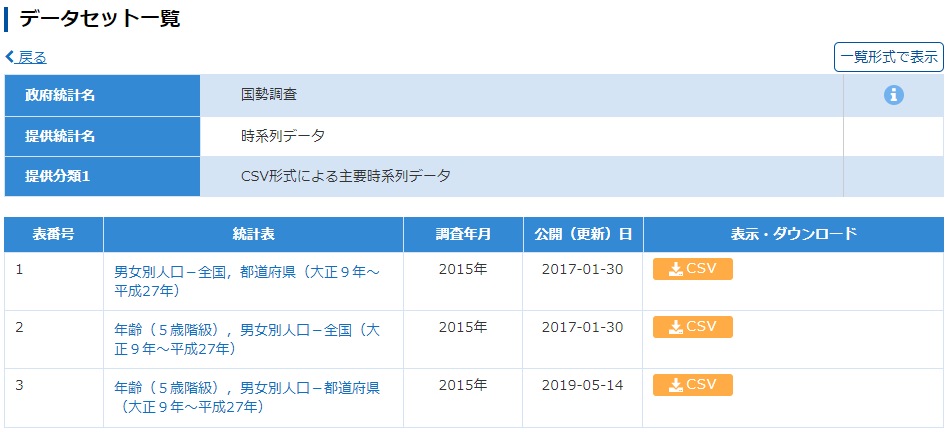
e-Stat を渉猟していると面白いファイルを見つけた.国勢調査は 1920 年から開始されており, 2020 年 3 月現在では最新の調査結果は 2015 年のものである.20 回分の人口データが一つのファイルにまとめられており,グラフ化するには格好のデータである.
年齢(5歳階級),男女別-都道府県(大正9年~平成27年)というファイルである.リンク先のページにはファイルが 3 つあるが,最後のものが最も粒度が細かいので,これをグラフ化する.