SQL Serverでサブクエリとウィンドウ関数のパフォーマンスを比較した.用いたデータベースはHeatStrokeDBで,熱中症の搬送人員と最高気温との相関関係を可視化し閾値をχ二乗検定するで作成したものである.
比較するツールはSET STATISTCS PROFILE ONコマンドである.クエリストアは筆者の環境では機能しなかった.

Co-evolution of human and technology

SQL Serverでサブクエリとウィンドウ関数のパフォーマンスを比較した.用いたデータベースはHeatStrokeDBで,熱中症の搬送人員と最高気温との相関関係を可視化し閾値をχ二乗検定するで作成したものである.
比較するツールはSET STATISTCS PROFILE ONコマンドである.クエリストアは筆者の環境では機能しなかった.
データベースのテーブルに適切なインデックスを設定するのはクエリを高速化するうえで重要な施策である.今回,空間演算にコストがかかっていたクエリが空間インデックスの設定により高速化したので報告する.
二乗平均平方根誤差とは英語では Root Mean Squared Error (RMSE) と書く.真値と予測値との乖離(誤差)を二乗し,その平均値をとり,その平方根を求めた値のことである.非負の値を取り,0に近いほど優れたモデルであることを示唆する.
今回使用するのはe-Statからの社会疫学的指標を加えて熱中症搬送人員数を分析するで使用したデータベースである.先の記事では回帰モデルを評価する指標が必要との認識であった.
都道府県別の熱中症搬送人員数の予測と実際をEXCELの組み合わせグラフで描くでは独立変数として日最高気温,日平均水蒸気圧,65歳以上人口,人口密度を投入し都道府県別の熱中症搬送人員数を予測した.以前の記事ではe-Statからの社会疫学的指標を加えて熱中症搬送人員数を分析した.社会疫学的指標としては日最高気温,日平均水蒸気圧,都道府県人口に加えて過去30日間の平均気温,エアコン保有台数,年間収入のジニ係数,光熱・水道費,実収入,第1次産業就業者比率,第2次産業就業者比率,都市公園数,都市緑化割合,自然公園割合,自然公園数,生活保護被保護人員である.
今回は社会疫学的指標を独立変数として加えた熱中症搬送人員数の予測と実際を示す.
熱中症搬送人員数に日最高気温と平均水蒸気圧が強く影響することは疑いの余地がない.他の気象条件として風速や雲量が負の影響をおよぼす可能性はないだろうか.言い換えると,風速が強ければ熱中症を発症する可能性が下がることは考えられないか,晴れよりも曇りや雨の日は熱中症を発症する可能性が下がることは考えられないかということである.
前回の記事で熱中症データベースに平均風速をインポートした.詳細は割愛するが,同様の手順で平均雲量のデータもインポートできる.
今回は説明変数として日最高気温,平均水蒸気圧に平均風速および平均雲量を加えて一般化線形モデルにて解析を行い,tree関数で可視化を試みた.
気象庁の過去の気象データ・ダウンロードからは膨大な気象データをダウンロードできる.今回の記事ではSQL Server内に構築した熱中症データベースに日平均風速のテーブルを追加する.
医療機関テーブルには二次医療圏コードが存在しない.そのため,ある医療機関がどの二次医療圏に属しているかを調べるには空間データを調べる必要がある.空間データは計算コストが高く,テーブルの結合条件に STWIthin() メソッドを使うのは時間がかかる.そのため,医療機関テーブルに二次医療圏コードを追加しようと考えた.
以前の記事で国土交通省の国土数値情報の河川データが破損していると口を酸っぱくして述べたが,いつの間にか修復されていた.修復されていたのは北海道および茨城県のテーブル構造である.岐阜県と三重県のファイルは破損したままであり,修復を要した.
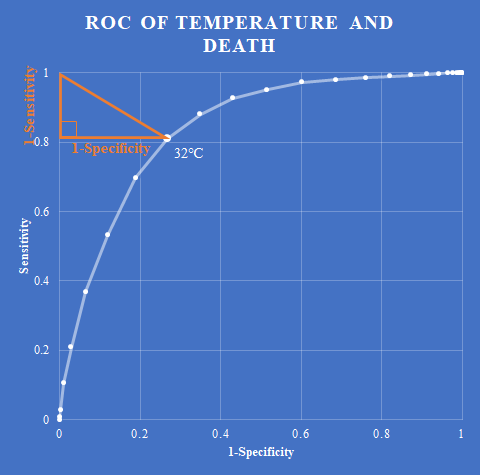
前回は感度と特異度をユーザー定義のスカラー値関数として定義した.今回はそれを利用して閾値を求める.
“ROC曲線の閾値を求めるストアドプロシージャまたはインラインテーブル値関数をSQL Serverで定義する” の続きを読む
前回の記事では階乗を求めるユーザー定義関数を経てFisherの直接確率をストアドプロシージャで求めた.今回は四分表から感度と特異度を求めたい.