SQL Serverでサブクエリとウィンドウ関数のパフォーマンスを比較した.用いたデータベースはHeatStrokeDBで,熱中症の搬送人員と最高気温との相関関係を可視化し閾値をχ二乗検定するで作成したものである.
比較するツールはSET STATISTCS PROFILE ONコマンドである.クエリストアは筆者の環境では機能しなかった.

Co-evolution of human and technology

SQL Serverでサブクエリとウィンドウ関数のパフォーマンスを比較した.用いたデータベースはHeatStrokeDBで,熱中症の搬送人員と最高気温との相関関係を可視化し閾値をχ二乗検定するで作成したものである.
比較するツールはSET STATISTCS PROFILE ONコマンドである.クエリストアは筆者の環境では機能しなかった.
データベースのテーブルに適切なインデックスを設定するのはクエリを高速化するうえで重要な施策である.今回,空間演算にコストがかかっていたクエリが空間インデックスの設定により高速化したので報告する.
オーストラリアでの住所からのジオコーディングはGeoscape社が担当しており,そのプロジェクト名をG-NAFという.オーストラリア政府から補助金を受けており,2029年まで無料公開されることが決まっている.
データ数は1500万件以上,空間参照系はGDA94(EPSG: 4283)またはGDA2020(EPSG: 7844)である.
今回はSQL Serverでデータベースからテーブル作成,データのインポート,テーブルへの主キーと外部キーの作成までを行う.
二乗平均平方根誤差とは英語では Root Mean Squared Error (RMSE) と書く.真値と予測値との乖離(誤差)を二乗し,その平均値をとり,その平方根を求めた値のことである.非負の値を取り,0に近いほど優れたモデルであることを示唆する.
今回使用するのはe-Statからの社会疫学的指標を加えて熱中症搬送人員数を分析するで使用したデータベースである.先の記事では回帰モデルを評価する指標が必要との認識であった.
総務省の公開しているe-Statには社会疫学的指標が多く含まれる.今回熱中症搬送人員数に様々な指標を加えて解析してみた.
説明変数として日最高気温,日平均水蒸気圧,都道府県人口に加えて過去30日間の平均気温,エアコン保有台数,年間収入のジニ係数,光熱・水道費,実収入,第1次産業就業者比率,第2次産業就業者比率,都市公園数,都市緑化割合,自然公園割合,自然公園数,生活保護被保護人員を加えた.
すべての変数が有意であったが,VIFを見ると多重共線性を疑わせる変数もあり,良いモデルとは言えない結果となった.
熱中症の搬送人員数が月平均気温と負の相関があるとの情報を得た.普段涼しい地域ほど日最高気温の上昇に弱いという意味である.普段涼しいということを表現するには過去30日間の日平均気温の平均を取ればよいだろうと判断した.こうなるとSQL Serverのウィンドウ関数の出番である.
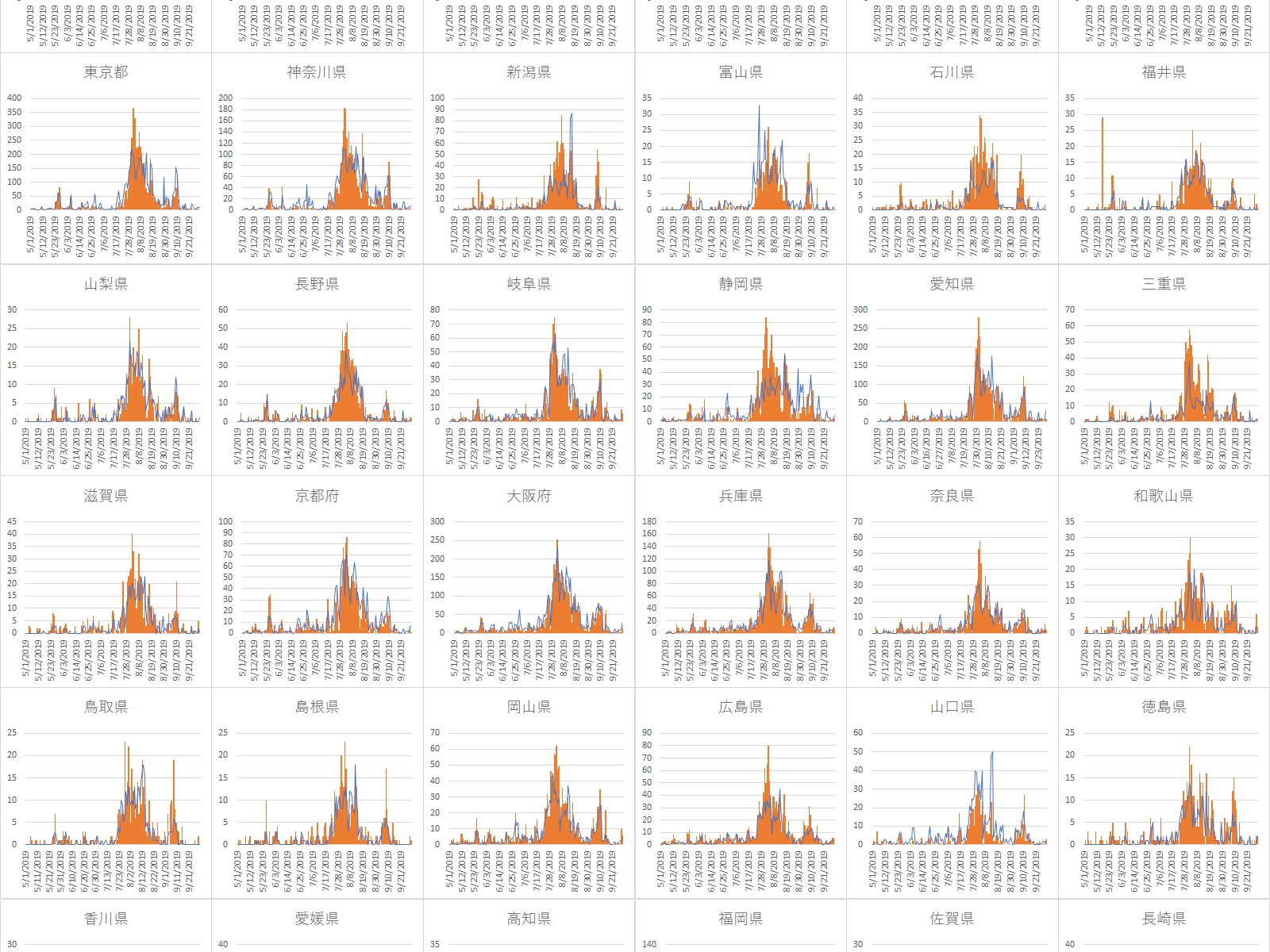
これまでの記事で日最高気温と平均水蒸気圧,各都道府県65歳以上人口および月から熱中症の搬送人員数を予測する回帰式の回帰係数を推定してきた.
今回はその回帰式を元に実際のデータと比較してみたい.対象は2019年の47都道府県とする.
以前の記事では都道府県人口の対数をオフセット項として一般化線形回帰分析を行った.実際のところ,年代別の搬送人員としては65歳以上の高齢者が圧倒的に多い.そのため,東京など労働人口の多いところでは予測性能が悪化する可能性がある.今回はオフセット項の都道府県人口を3区分に分け,65歳以上人口の対数をオフセット項として採用してみたところ予測性能が改善したと思われたので記事とした.
人体には暑熱馴化という機構がある.暑さに体が慣れることである.この機構を取り込んだモデルを構築してみた.
熱中症搬送人員数に日最高気温と平均水蒸気圧が強く影響することは疑いの余地がない.他の気象条件として風速や雲量が負の影響をおよぼす可能性はないだろうか.言い換えると,風速が強ければ熱中症を発症する可能性が下がることは考えられないか,晴れよりも曇りや雨の日は熱中症を発症する可能性が下がることは考えられないかということである.
前回の記事で熱中症データベースに平均風速をインポートした.詳細は割愛するが,同様の手順で平均雲量のデータもインポートできる.
今回は説明変数として日最高気温,平均水蒸気圧に平均風速および平均雲量を加えて一般化線形モデルにて解析を行い,tree関数で可視化を試みた.