二乗平均平方根誤差とは英語では Root Mean Squared Error (RMSE) と書く.真値と予測値との乖離(誤差)を二乗し,その平均値をとり,その平方根を求めた値のことである.非負の値を取り,0に近いほど優れたモデルであることを示唆する.
今回使用するのはe-Statからの社会疫学的指標を加えて熱中症搬送人員数を分析するで使用したデータベースである.先の記事では回帰モデルを評価する指標が必要との認識であった.

Co-evolution of human and technology
二乗平均平方根誤差とは英語では Root Mean Squared Error (RMSE) と書く.真値と予測値との乖離(誤差)を二乗し,その平均値をとり,その平方根を求めた値のことである.非負の値を取り,0に近いほど優れたモデルであることを示唆する.
今回使用するのはe-Statからの社会疫学的指標を加えて熱中症搬送人員数を分析するで使用したデータベースである.先の記事では回帰モデルを評価する指標が必要との認識であった.
都道府県別の熱中症搬送人員数の予測と実際をEXCELの組み合わせグラフで描くでは独立変数として日最高気温,日平均水蒸気圧,65歳以上人口,人口密度を投入し都道府県別の熱中症搬送人員数を予測した.以前の記事ではe-Statからの社会疫学的指標を加えて熱中症搬送人員数を分析した.社会疫学的指標としては日最高気温,日平均水蒸気圧,都道府県人口に加えて過去30日間の平均気温,エアコン保有台数,年間収入のジニ係数,光熱・水道費,実収入,第1次産業就業者比率,第2次産業就業者比率,都市公園数,都市緑化割合,自然公園割合,自然公園数,生活保護被保護人員である.
今回は社会疫学的指標を独立変数として加えた熱中症搬送人員数の予測と実際を示す.
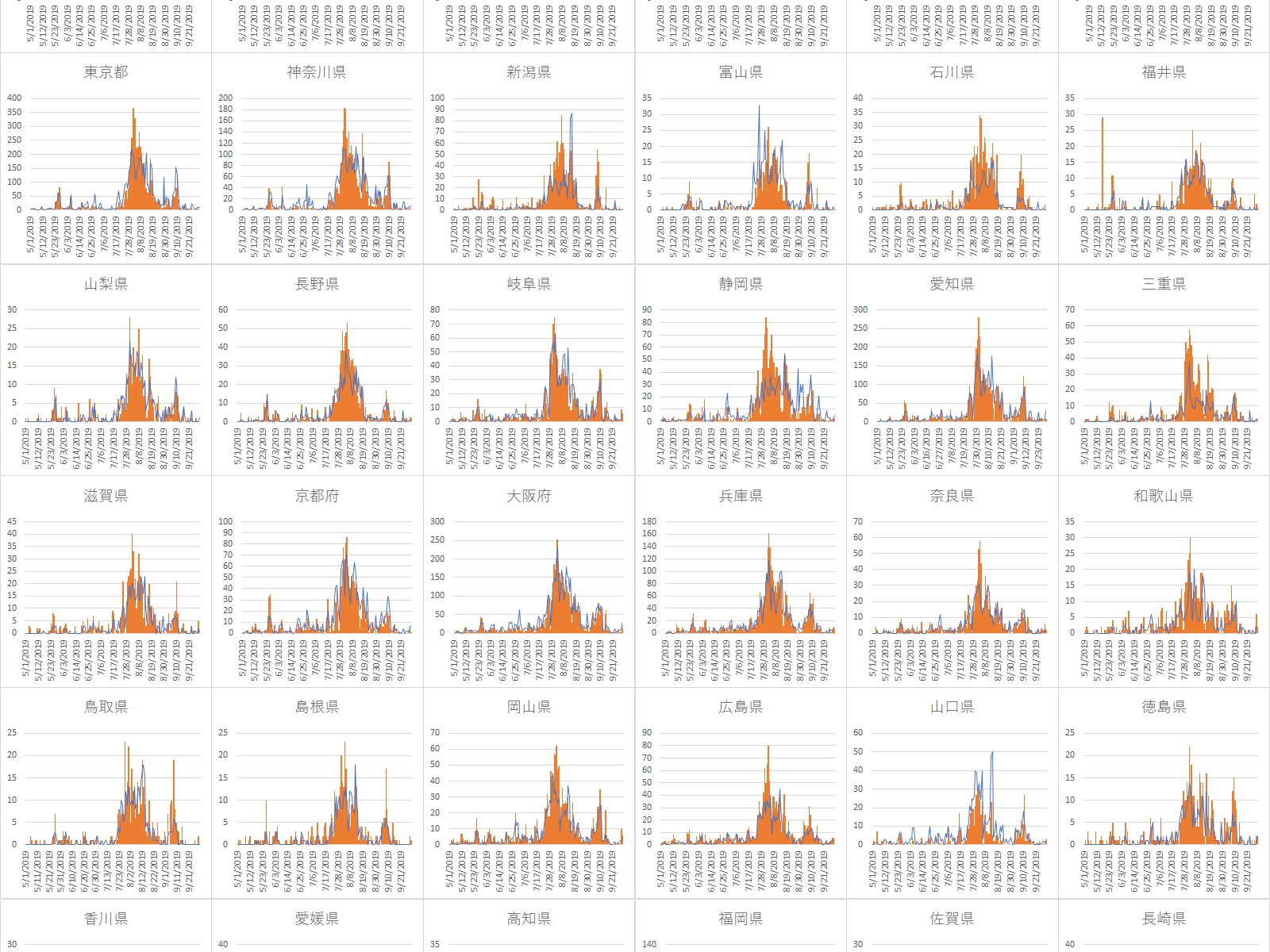
これまでの記事で日最高気温と平均水蒸気圧,各都道府県65歳以上人口および月から熱中症の搬送人員数を予測する回帰式の回帰係数を推定してきた.
今回はその回帰式を元に実際のデータと比較してみたい.対象は2019年の47都道府県とする.
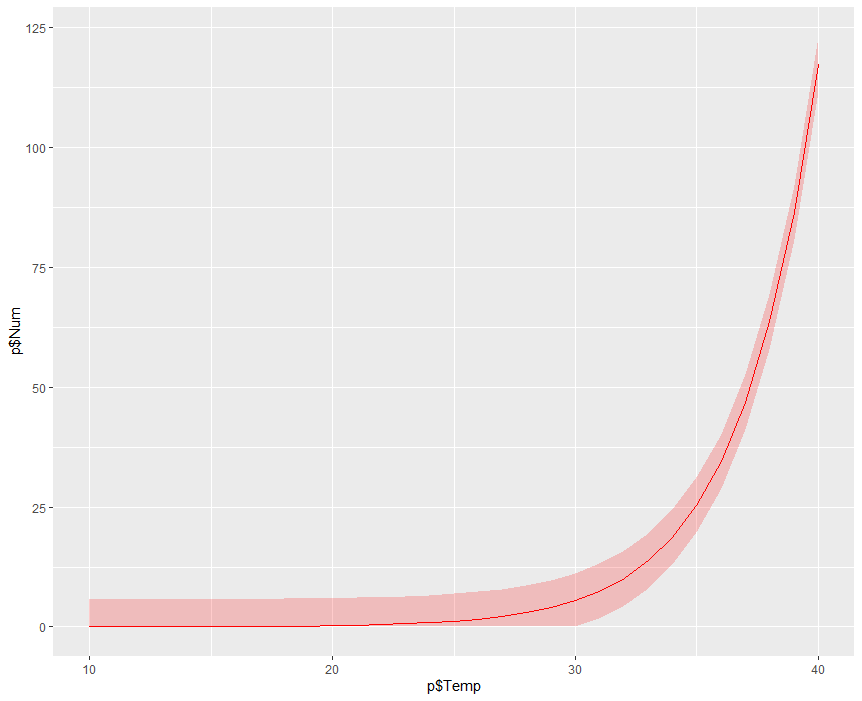
前回の記事では熱中症搬送人員数に対する日最高気温の回帰曲線を描いた.今回はポアソン分布に基づく搬送人員数の95%信頼区間を求める.

前回の記事では階乗の自然対数を求めるユーザー定義関数をSQL Serverで作成するを記述した.今回はそのユーザー定義関数を用いてFisherの直接確率を求めるストアドプロシージャを記述する.
Fisherの直接確率を求める際,階乗の計算が必要になる.しかし,引数が最大でも170までと使い勝手が良くない.これはプログラム言語の種類にかかわらず,データ長の制約が原因である.今回は対数を用いて階乗計算の引数の限界を超えるアイデアを共有したい.