河川データを都道府県別ではなく,水域別に抽出したい.そんな動機から QGIS と EXCEL の間を行ったり来たりしている.QGISで都道府県ごとの河川データをマージするではかなり無謀なことをやった.今回はもう少し丁寧にデータを扱ってみたい.
都道府県ごとの河川データを1つのcsvファイルに変換する

Co-evolution of human and technology
河川データを都道府県別ではなく,水域別に抽出したい.そんな動機から QGIS と EXCEL の間を行ったり来たりしている.QGISで都道府県ごとの河川データをマージするではかなり無謀なことをやった.今回はもう少し丁寧にデータを扱ってみたい.
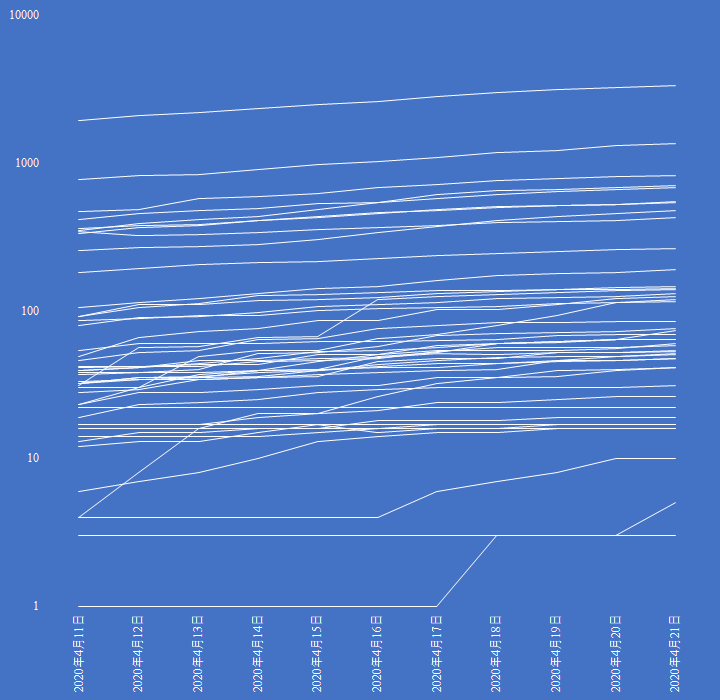
新型コロナウイルスのパンデミック宣言以降,Twitter でフォローしているアカウントに自然と相互協調の動きがみられる.
厚労省が「地域ごとのまん延の状況に関する指標等」の公表を開始。
— にゃんこそば (@ShinagawaJP) 2020年4月23日
都道府県ごとの①確定患者数、②リンクが不明な患者数、③相談件数、④PCR検査の実施数…と、必要な情報を一通り網羅しています。
が、ファイルはまさかのPDF形式。ExcelかCSVも提供してくれれば…https://t.co/Ox5rU6m1Xo
このツイートから始まった一連のやりとりで,厚労省の発表した PDF からテーブルを抽出するくだりに注目した.
失礼します。今、マクロソフト Power BI デスクトップを使用したところ無事PDFを読み込めました。また、列のピボット解除という機能を使うことで、クロス集計表を添付のような集計用フォーマットに加工できます。 pic.twitter.com/FEV0SBSito
— Akira Takao (@modernexcel7) 2020年4月23日
今回はここを画像つきで実施してみた.
“厚労省「地域ごとのまん延の状況に関する指標等」の PDF から Power BI Desktop でデータを抽出し EXCEL のグラフに表現する” の続きを読む
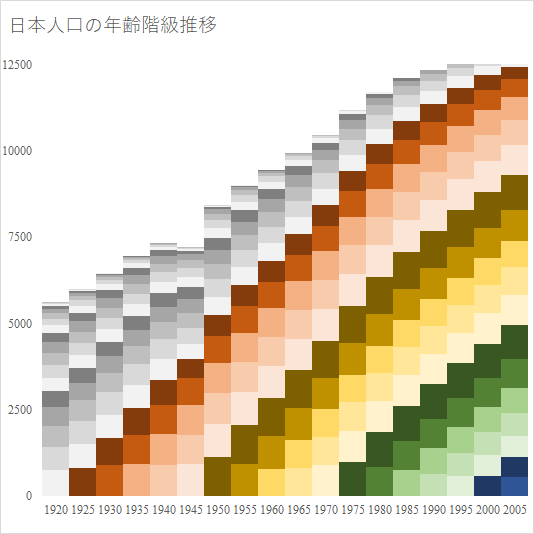
人口統計は最も重要な基幹統計の一つである.総務省の e-Stat は確かに有用であるが,かゆいところに手が届かない.例えば「市区町村ごと,年齢5歳階級ごとの人口構成の国勢調査ごとの推移を知りたい」という要求には全く無力である.
主として技術的な理由によるものと,統計調査の粒度の細かさによる.技術的な理由としては,データベースの画面表示セル数の上限を容易に超えてしまうデータ量になってしまうことである.しかし,根本的な理由は調査の粒度の細かさである.
2005 年以前と 2010 年以降とでは調査の精度が違う.今後は高精度なデータファイルが e-Stat に掲載されていくものと思われるが,2005 年以前に関しては都道府県より細かい粒度は存在しない.そこを求めると手作業になってしまい,現実的ではない.国立社会保障・人口問題研究所ならデータを持っているかもしれない.
2020 年は国勢調査の年にあたる.総務省にはできるだけ細かい粒度でのデータ掲載を望むものである.
基幹データベースが Oracle DB の場合,最も基本的なデータ抽出方法の一つに SQL*Plus がある.SI Object Browser などもあるが基本有償で,個人で購入するには少し敷居が高い.
SQL*Plus でどこまでできるかは勉強中のため未知数だが,あらかじめ .sql ファイルを作っておいて実行するなら心理的な障壁も下がる.
日本の人口統計は総務省が 5 年おきに行う国勢調査が元になっている.日本の市の人口順位をEXCELにダウンロードして散布図に描くでは日本全国の都市の人口増減率と人口の関係を時系列で流すとどう推移するか予測した.今回はその予測が実態と合っているか乖離しているかの検証を行う.

カレンダーアプリは Google カレンダーに依存している.Google カレンダーから日付とイベント,詳細を抽出する必要が出てきたため,小一時間調べた方法を備忘録として残しておく.

今回は泥臭い話になる.どんなプログラミングでも同じだが,一発で意図通りに動くことはまずない.試行錯誤の末,ようやくこんなものかという出来上がりである.SQL においても同じだ.クエリでは NULL の扱いが難しい.そんなところを感じ取ってもらえればと思う.
先日公開した記事トレーニングの最適化:安全な筋力トレーニングにおける新しい進展で参照していた引用元の論文からダウンロードできるファイルは PDF であるが,画像として保存されており,テキスト情報が抽出できなかった.以前ならスキャナから OCR ソフトで文字情報を抽出したが,最近だと Google ドキュメントが優秀なので,こちらを使ってテキスト情報を抽出してみた.