これまでの記事で日最高気温と平均水蒸気圧,各都道府県65歳以上人口および月から熱中症の搬送人員数を予測する回帰式の回帰係数を推定してきた.
今回はその回帰式を元に実際のデータと比較してみたい.対象は2019年の47都道府県とする.

Co-evolution of human and technology
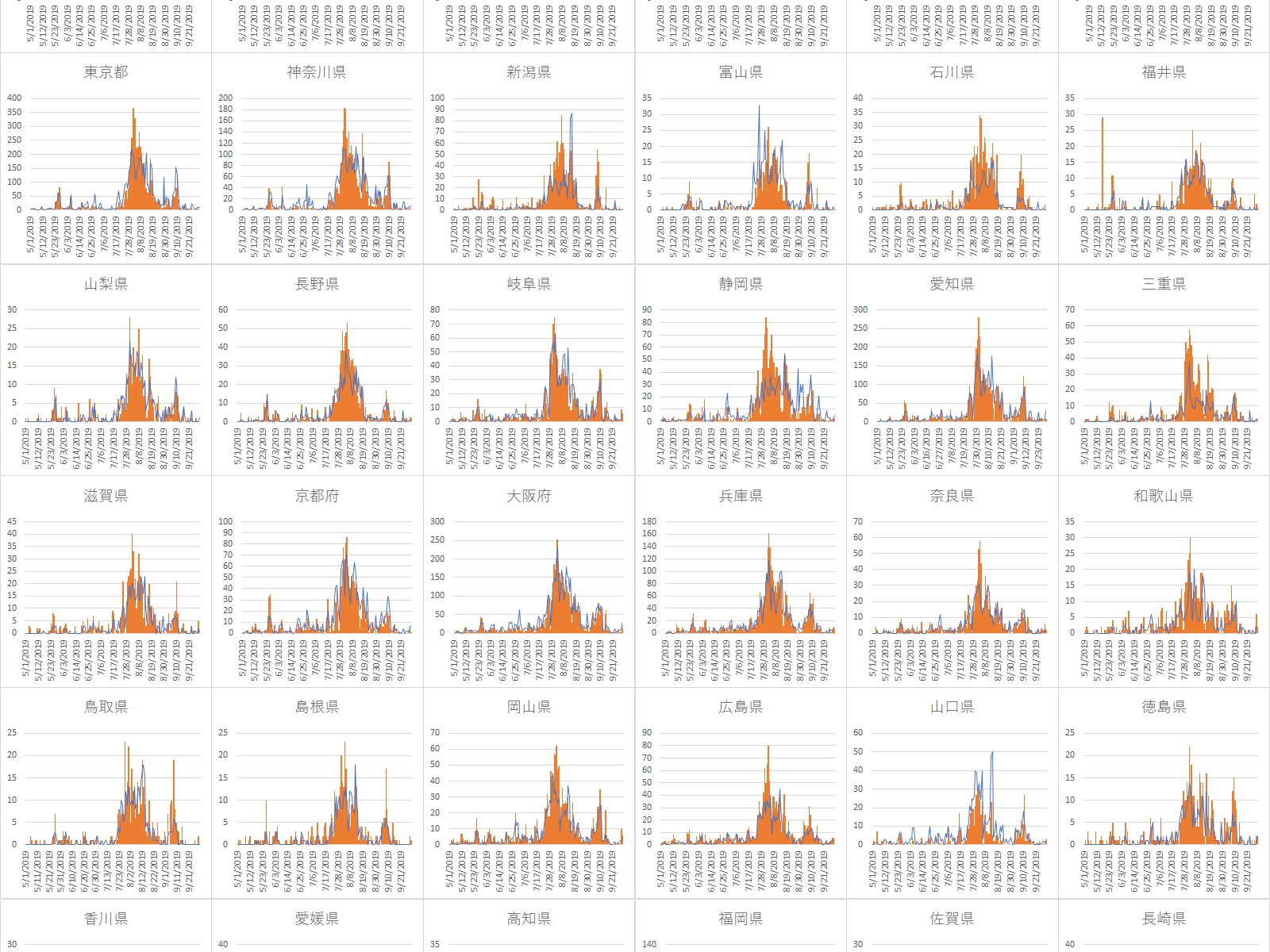
これまでの記事で日最高気温と平均水蒸気圧,各都道府県65歳以上人口および月から熱中症の搬送人員数を予測する回帰式の回帰係数を推定してきた.
今回はその回帰式を元に実際のデータと比較してみたい.対象は2019年の47都道府県とする.
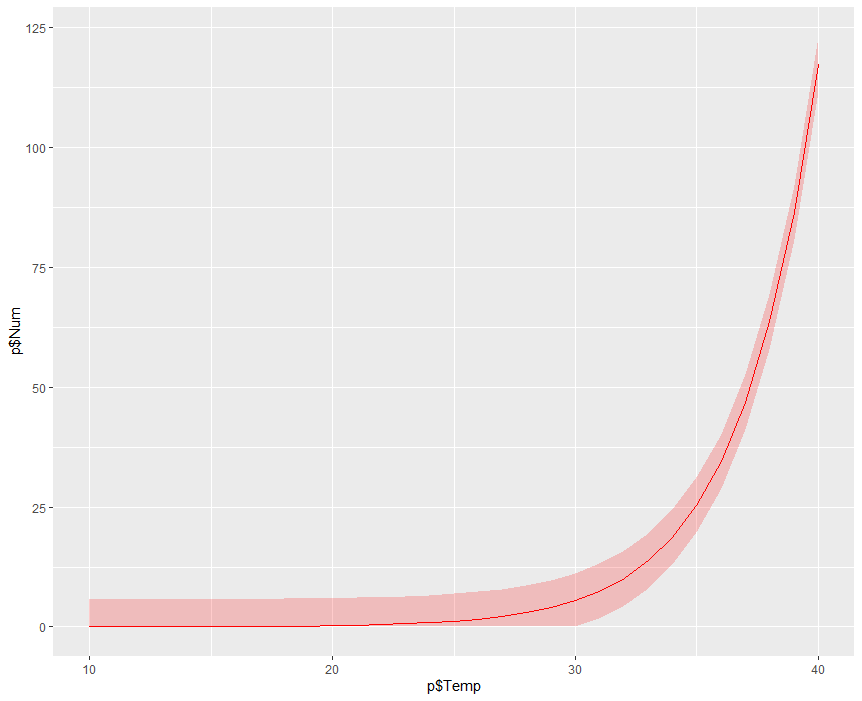
前回の記事では熱中症搬送人員数に対する日最高気温の回帰曲線を描いた.今回はポアソン分布に基づく搬送人員数の95%信頼区間を求める.
以前,熱中症搬送人員数は日最高気温と相関関係があり,片対数グラフで直線になると述べた.今回はポアソン回帰モデルおよび負の二項分布モデルで熱中症搬送人員数に対する日最高気温と平均水蒸気圧の回帰係数を推定する.
“ポアソン回帰モデルおよび負の二項分布モデルを用いて熱中症搬送人員数に対する日最高気温と平均水蒸気圧の回帰係数を推定する” の続きを読む

Excelのピボットテーブルでクロス集計から統計解析まででも書いたが,統計解析の醍醐味は多変量解析にある.単変量解析では変数間の交絡の可能性が否定できず,重要なポイントを見落とすことがある.
統計の専門家ではないので完全に我流の方法であるが,多変量解析における変数選択の参考になるかと思い,記しておく.
過去に査読者とのやり取りの中で,変数選択の方法をかなり具体的に指示され,その通りにしないと通さないぞという言外の圧力を感じたことがある.
その時は違和感を感じつつもその通りにしたら通ったのだが,どうにもその違和感がずっと残っていた.いわく,単変量解析で有意になった変数のみを組み合わせて多変量解析に持ち込む,という手法だったのだが,本当にそれで良かったのだろうか?