医療機関コードは10桁の数値からなる.最初の2桁が都道府県コード,次の1桁が区分点数コード,後半7桁が医療機関番号である.医療機関番号は都道府県内では一意であるが,都道府県をまたぐと一意ではなくなる.今回はその医療機関番号から医療機関コードを取得する方法を投稿する.
全国の医療機関コードを取得する


Co-evolution of human and technology
医療機関コードは10桁の数値からなる.最初の2桁が都道府県コード,次の1桁が区分点数コード,後半7桁が医療機関番号である.医療機関番号は都道府県内では一意であるが,都道府県をまたぐと一意ではなくなる.今回はその医療機関番号から医療機関コードを取得する方法を投稿する.
世界各国の人口推移およびGDP推移を取得したい.そんな場合は国連や世界銀行のデータを活用する.今回は国連から人口推移,世界銀行からGDP推移のデータをそれぞれ取得したので経緯を紹介する.
Microsoft の公式サイト,英語なら取得は容易であるが,当然日本語は取得できない.今回は日本語サイトから英語と日本語の両者を取得しようと試みた.
結論から言うと,この記事で述べた方法で全ての日本語と英語とが分離できたわけではない.2 バイト文字と 1 バイト文字との分離という手法を用いたが,最終的には手動での対応が必要だった.
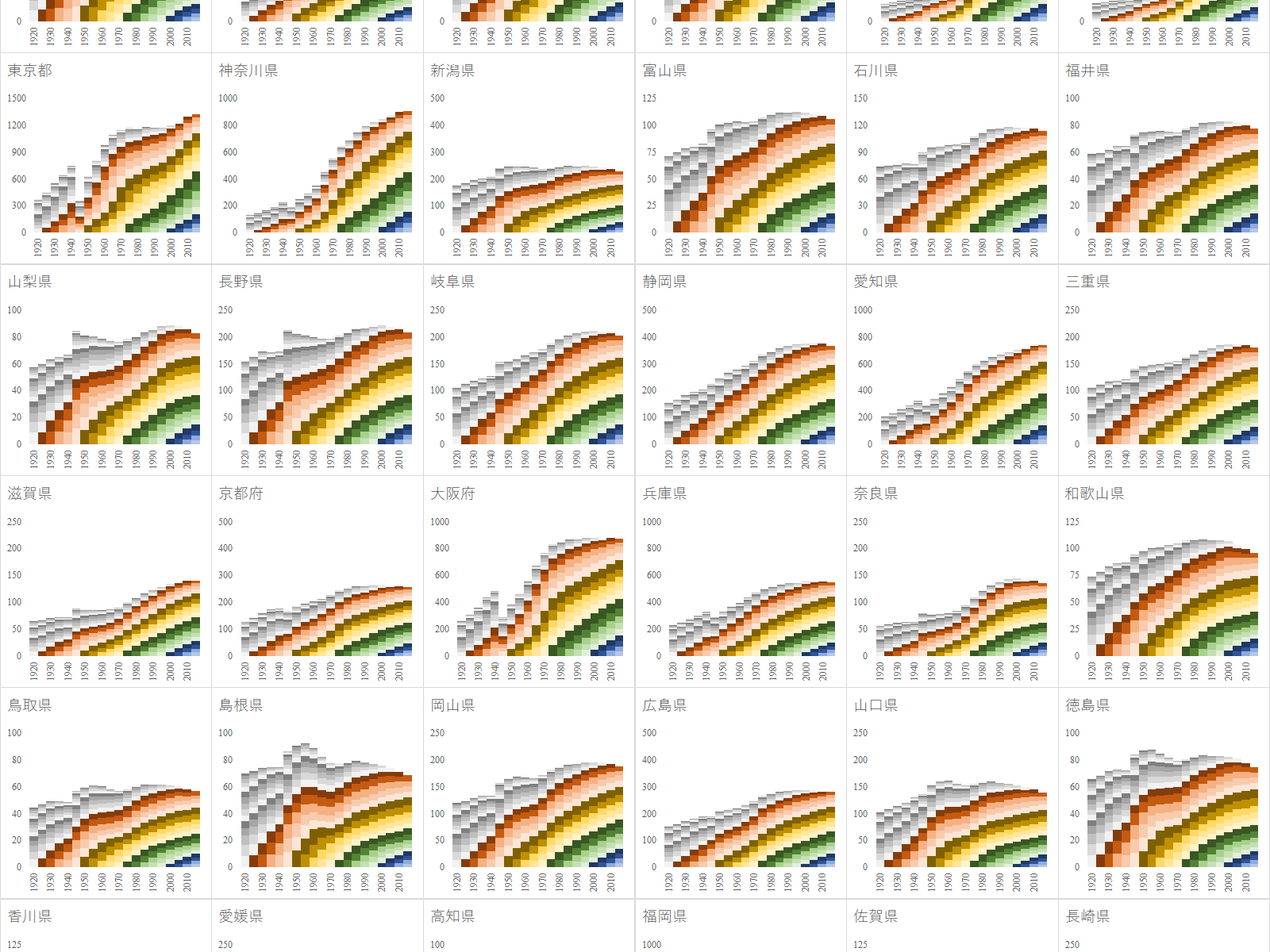
e-Stat を渉猟していると面白いファイルを見つけた.国勢調査は 1920 年から開始されており, 2020 年 3 月現在では最新の調査結果は 2015 年のものである.20 回分の人口データが一つのファイルにまとめられており,グラフ化するには格好のデータである.
年齢(5歳階級),男女別-都道府県(大正9年~平成27年)というファイルである.リンク先のページにはファイルが 3 つあるが,最後のものが最も粒度が細かいので,これをグラフ化する.
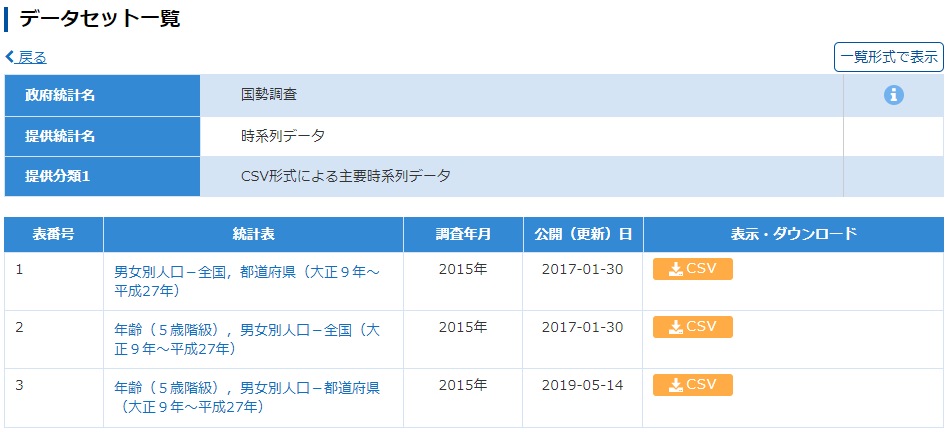
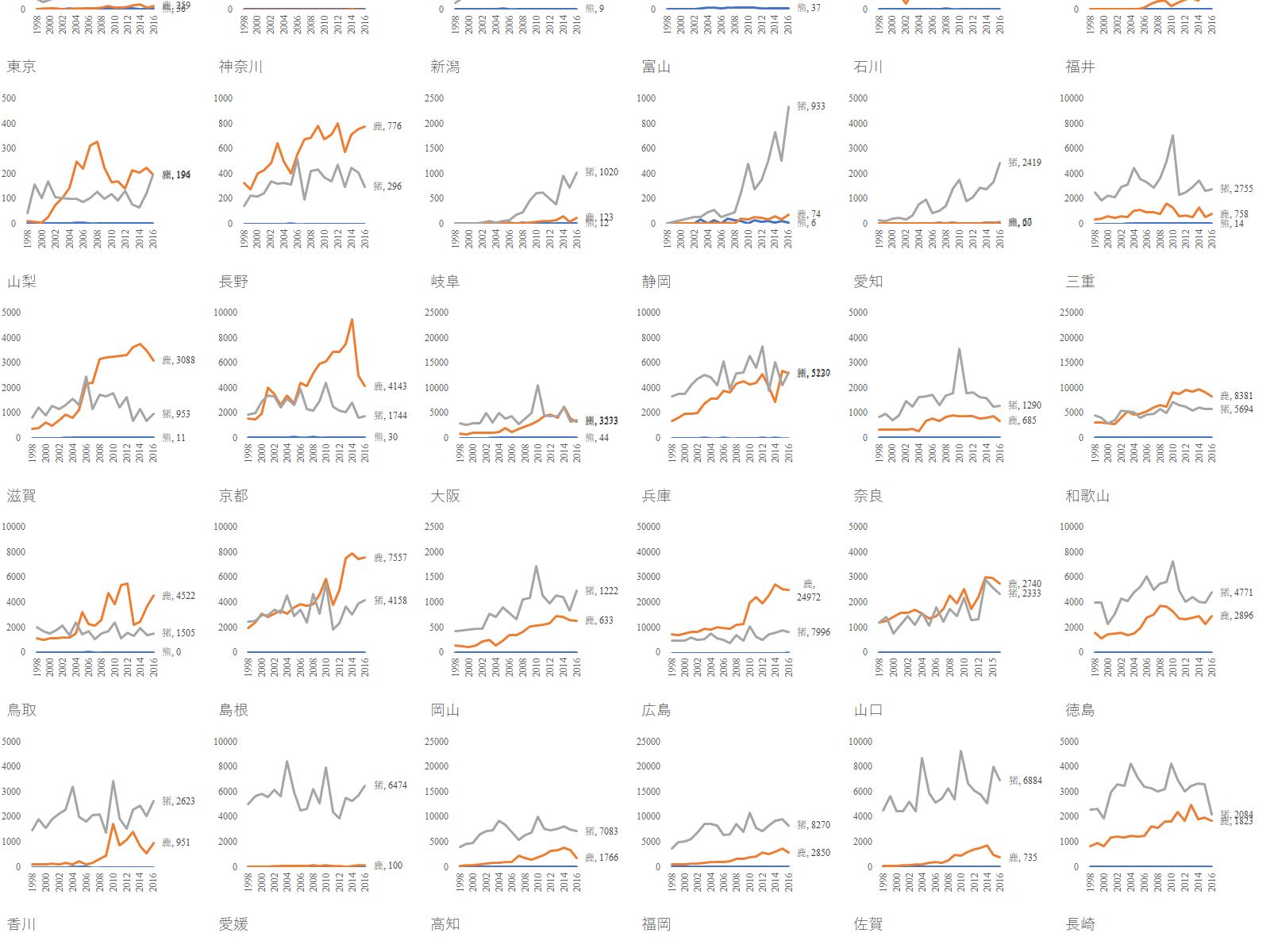
また面倒な統計を見つけてしまった.Power Query に食わせれば早いのかも知れないが,どうにも埒が明かないので手動でデータを整形することになった.頼むから第一正規形で公開してくれ…

EXCEL のワークシートの仕様上,100 万件を超えるデータは扱えない.これは大規模なデータを扱う際の制約である.180万件のデータをPower Queryで処理してEXCELがオーバーフローした話 でも述べたが,この制約を乗り越えてデータをインポートするにはデータモデルに読み込むほかはない.
SQL Server で PowerQuery が使えればこういった制約を回避できるのだが,ないものは仕方がない.今回は PowerPivot を用いてデータモデルに蓄積したデータを取り出す方法を見つけたので備忘録として記す.
EXCEL のワークシートに格納できるレコード数は 1,048,576 行である.今回 e-Stat からダウンロードしたファイルをピボット解除したらその上限を超えてしまったのでその記事を書こう.