国土数値情報の洪水浸水想定区域データをQGISで表現するではバッチプロセスで属性テーブルの属性をファイル名に取り出す部分でつまづいていた.今回QGISのコミュニティで質問した結果回答が得られたので結果を公開する.
“国土数値情報の想定最大規模の洪水浸水想定区域を浸水深ランクコードごとにQGISのバッチプロセスで融合する” の続きを読む

Co-evolution of human and technology
国土数値情報の洪水浸水想定区域データをQGISで表現するではバッチプロセスで属性テーブルの属性をファイル名に取り出す部分でつまづいていた.今回QGISのコミュニティで質問した結果回答が得られたので結果を公開する.
“国土数値情報の想定最大規模の洪水浸水想定区域を浸水深ランクコードごとにQGISのバッチプロセスで融合する” の続きを読む
Microsoft の公式サイト,英語なら取得は容易であるが,当然日本語は取得できない.今回は日本語サイトから英語と日本語の両者を取得しようと試みた.
結論から言うと,この記事で述べた方法で全ての日本語と英語とが分離できたわけではない.2 バイト文字と 1 バイト文字との分離という手法を用いたが,最終的には手動での対応が必要だった.
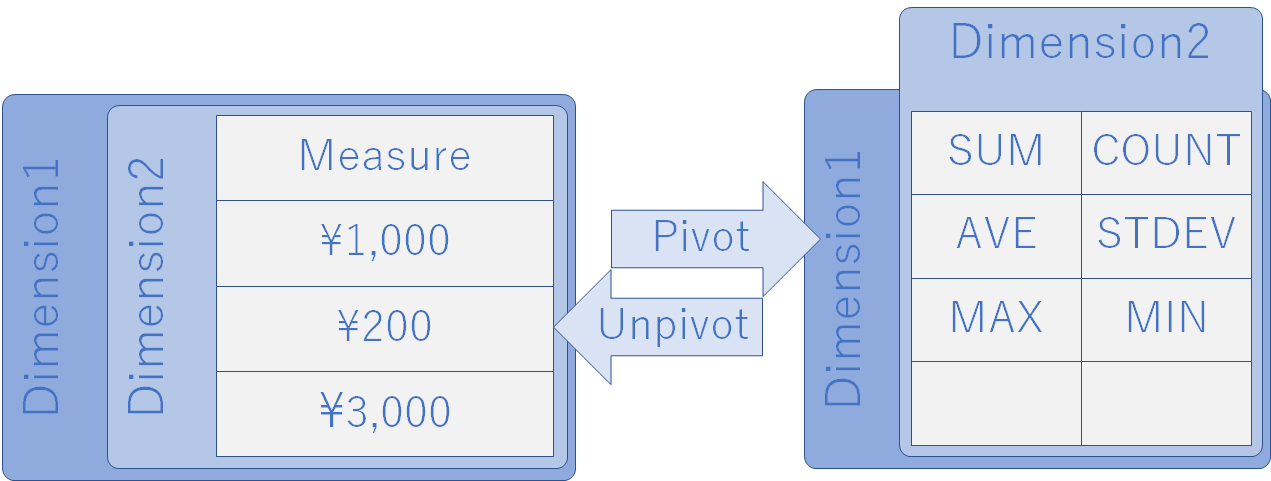
EXCEL のワークシートに格納できるレコード数は 1,048,576 行である.今回 e-Stat からダウンロードしたファイルをピボット解除したらその上限を超えてしまったのでその記事を書こう.
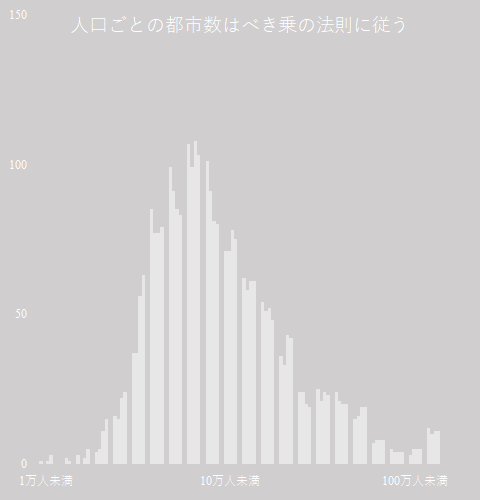
総務省統計ポータル e-Stat からのデータに全国の市区町村の人口推移があった.マーク・ブキャナンの「歴史はべき乗則で動く」の p 261 に「人口が半分の都市は四つある」とある.本当だろうか.検証してみた.
最近はとにもかくにも Power Query である.しかしながら,そのプロセスを VBA で記述したものを見ることが少ない.検索の仕方が悪いだけかも知れないが.
今回は外部データベースへの接続として Ubuntu 上の SQL Server を選んでみた.今回,Windows 上の SQL Server Management Studio から Ubuntu 上の SQL Server にデータベースを作成し,テーブルを挿入するの記事で作成したデータベースがあったので,これに接続してみることにした.
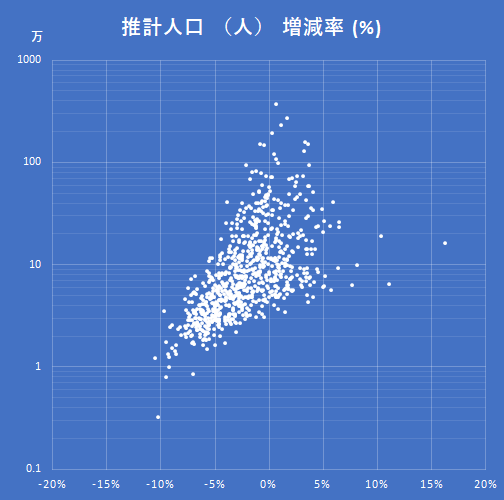
過去5年間の人口増減率から自治体の将来を予測するでは日本の都市の運命を占った.その元となるデータをダウンロードして散布図にする方法を述べる.
Ubuntu 上の SQL Server に Windows 上の SQL Server Management Studio や SPSS から接続する方法についてはわかった.
では,Power BI などの BI ツールはどうだろう?本稿ではその方法を概説する.

Excelのピボットテーブルでクロス集計から統計解析まででも書いたが,統計解析の醍醐味は多変量解析にある.単変量解析では変数間の交絡の可能性が否定できず,重要なポイントを見落とすことがある.
統計の専門家ではないので完全に我流の方法であるが,多変量解析における変数選択の参考になるかと思い,記しておく.
過去に査読者とのやり取りの中で,変数選択の方法をかなり具体的に指示され,その通りにしないと通さないぞという言外の圧力を感じたことがある.
その時は違和感を感じつつもその通りにしたら通ったのだが,どうにもその違和感がずっと残っていた.いわく,単変量解析で有意になった変数のみを組み合わせて多変量解析に持ち込む,という手法だったのだが,本当にそれで良かったのだろうか?
筋トレをしていて,「自分の背中を見たい.それもリアルタイムで」,そう思ったことのある人は俺だけではないはずだ.今回は 120 円でそんな願いを叶えよう.
“自分の背中を見たい?そんなあなたにCamera Plusを” の続きを読む