ベクタデータは拡大しても劣化がないが,データサイズが大きいため,環境によっては動作が極端に重くなる.
これといった決定打があるわけではないが,事前の準備があると少しは取り扱いが楽になる.

Co-evolution of human and technology
ベクタデータは拡大しても劣化がないが,データサイズが大きいため,環境によっては動作が極端に重くなる.
これといった決定打があるわけではないが,事前の準備があると少しは取り扱いが楽になる.
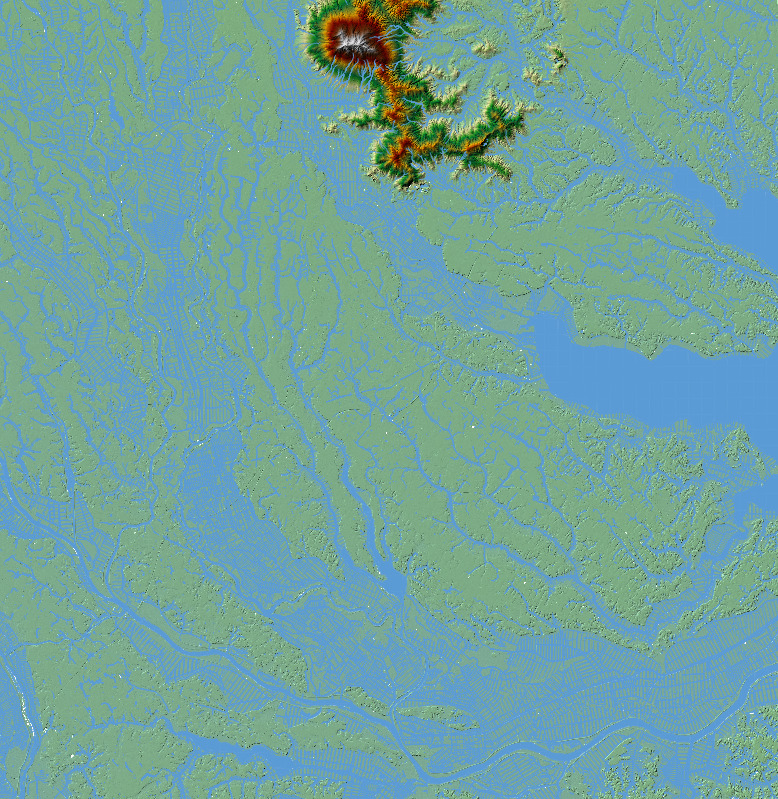
現時点で何を目指しているのか自分でもはっきりした形が見えているわけではないが,とりあえず地図上に河川や湖沼などを描画したい.
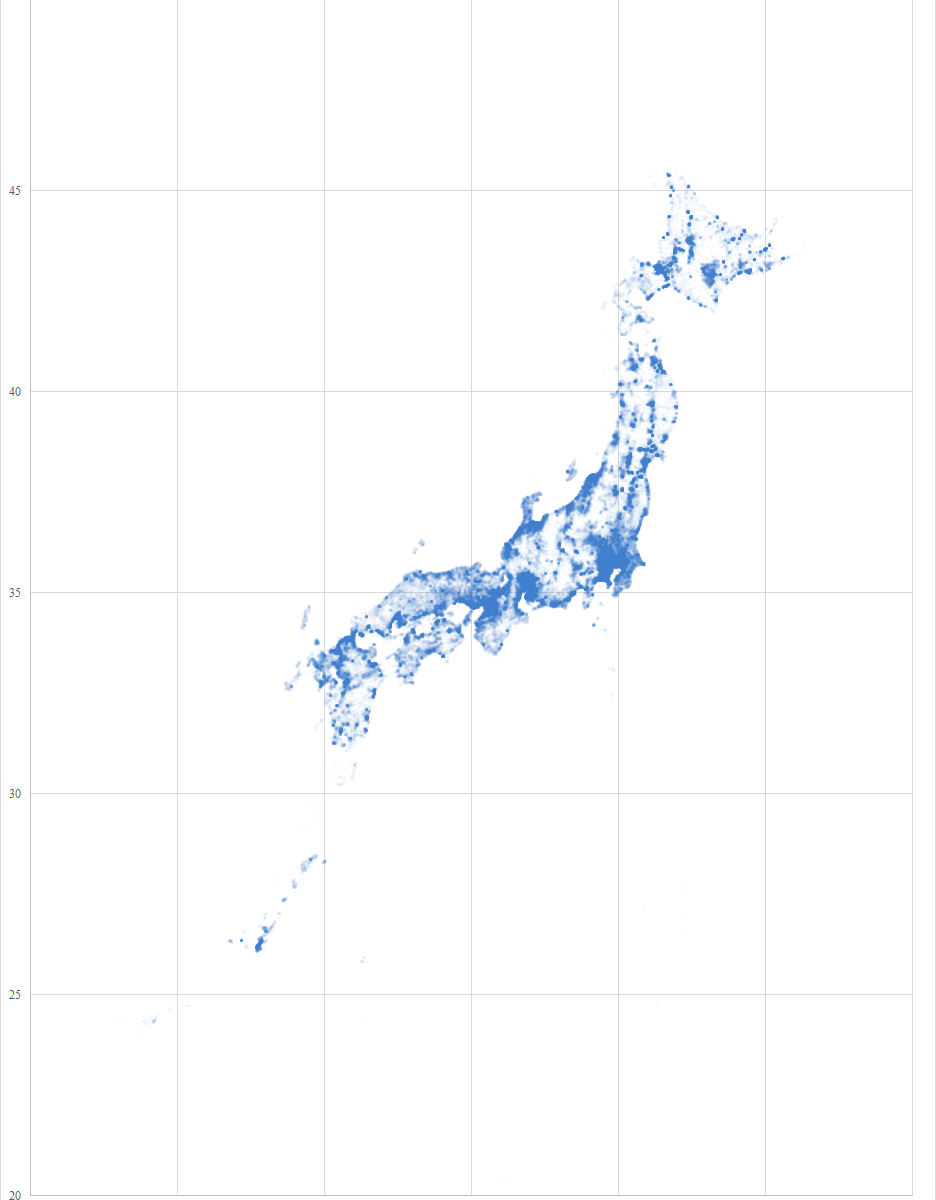
国土交通省のサービスの一つに位置参照情報ダウンロードサービスがある.何気なくファイルをダウンロードして,思いがけない発見があったため,記事を書くことにした.
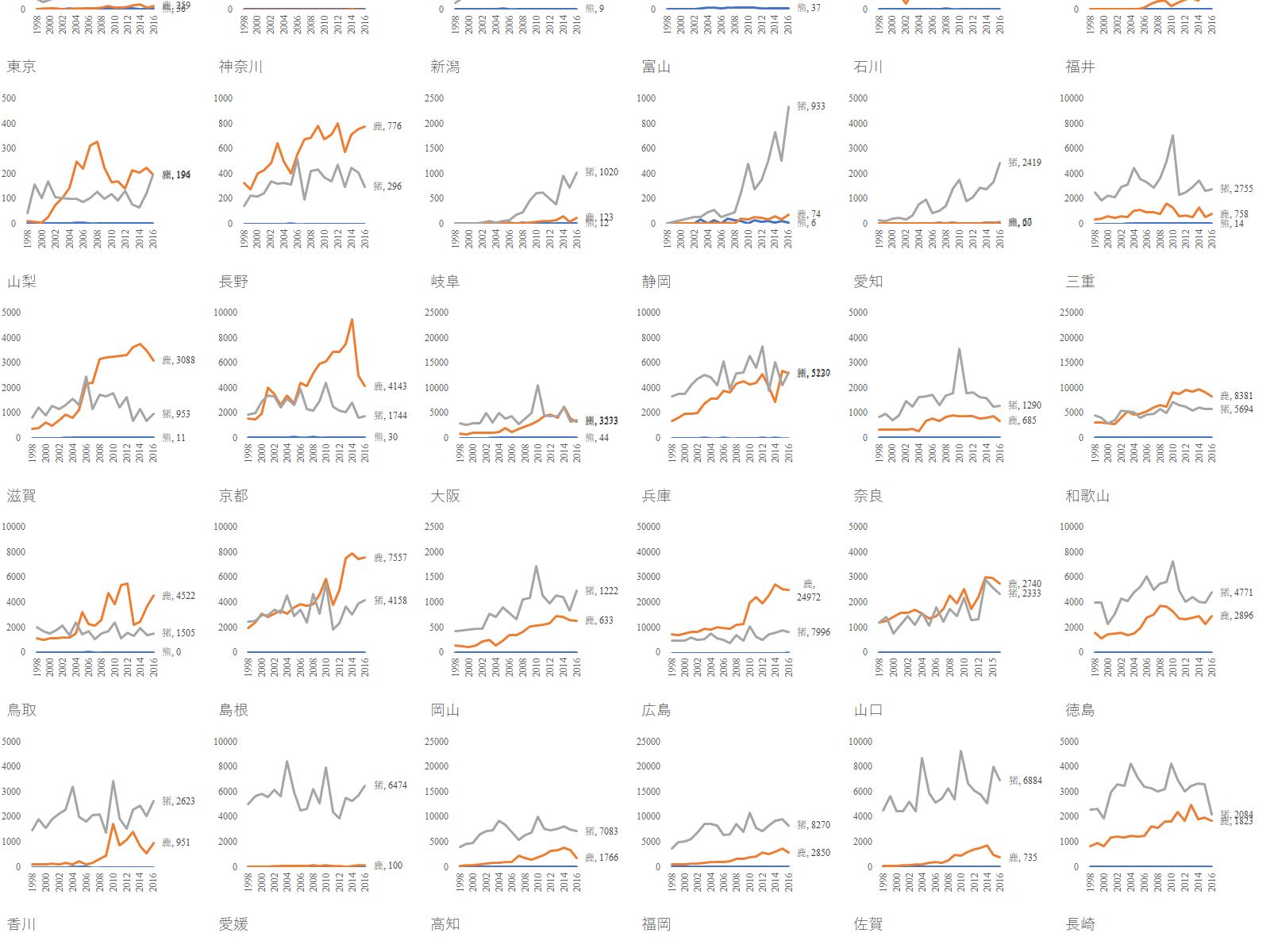
また面倒な統計を見つけてしまった.Power Query に食わせれば早いのかも知れないが,どうにも埒が明かないので手動でデータを整形することになった.頼むから第一正規形で公開してくれ…
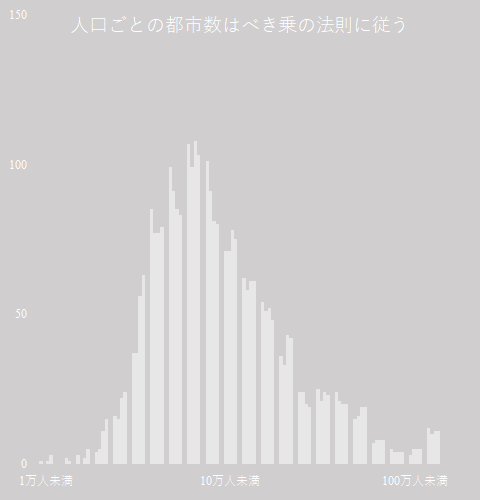
総務省統計ポータル e-Stat からのデータに全国の市区町村の人口推移があった.マーク・ブキャナンの「歴史はべき乗則で動く」の p 261 に「人口が半分の都市は四つある」とある.本当だろうか.検証してみた.
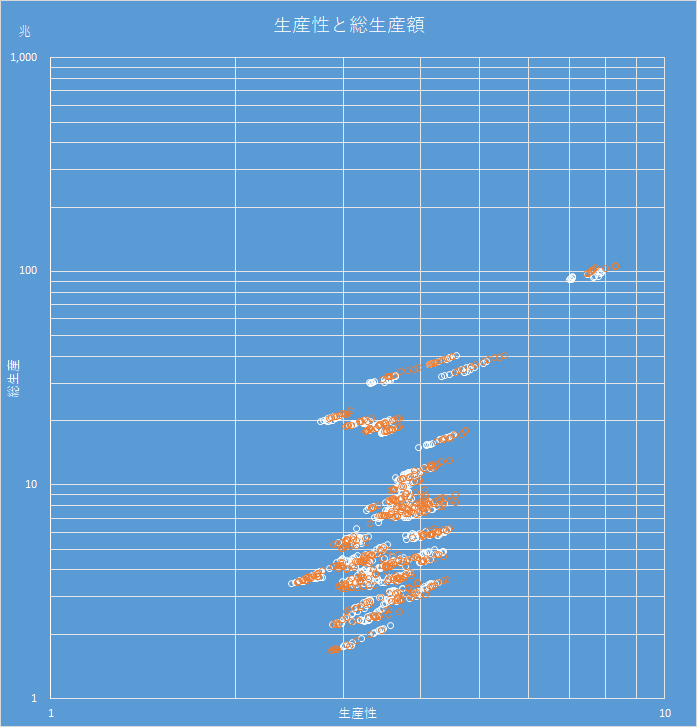
人口統計は国の将来を予測する重要な指標であるが,経済の指標である総生産も重要な指標である.これは国の元気さを示す値であり,報道では GDP と称されている.一人あたりの GDP とは生産性のことであり,国民の豊かさを示す値でもある.
マクロ経済学についてはほぼ素人だが,データを扱うにあたり,都道府県ごとの総生産額と生産性は欠かせない指標と思われたので,調査ついでに公開しよう.
日本の人口統計は総務省が 5 年おきに行う国勢調査が元になっている.日本の市の人口順位をEXCELにダウンロードして散布図に描くでは日本全国の都市の人口増減率と人口の関係を時系列で流すとどう推移するか予測した.今回はその予測が実態と合っているか乖離しているかの検証を行う.
先日公開した記事トレーニングの最適化:安全な筋力トレーニングにおける新しい進展で参照していた引用元の論文からダウンロードできるファイルは PDF であるが,画像として保存されており,テキスト情報が抽出できなかった.以前ならスキャナから OCR ソフトで文字情報を抽出したが,最近だと Google ドキュメントが優秀なので,こちらを使ってテキスト情報を抽出してみた.