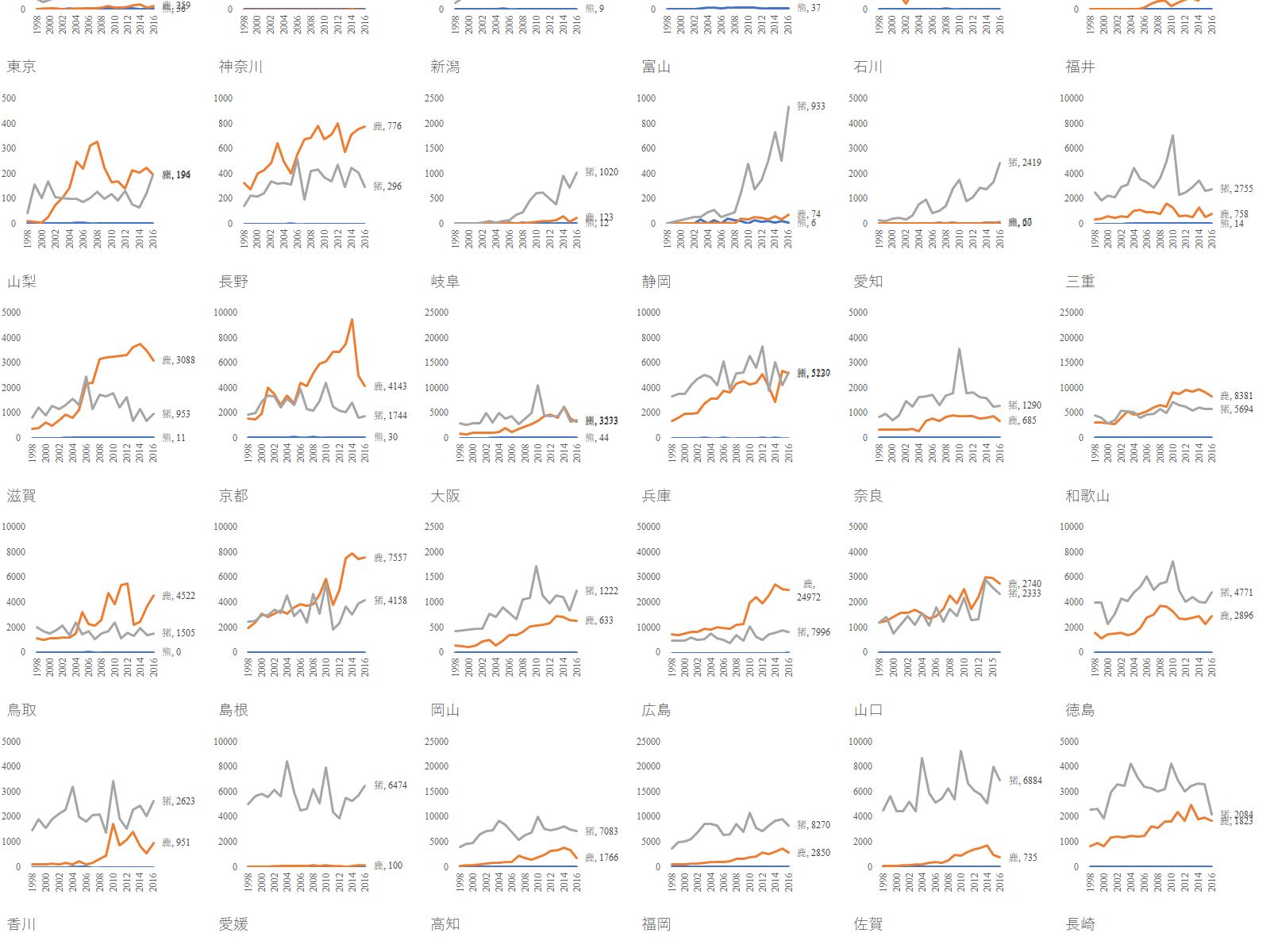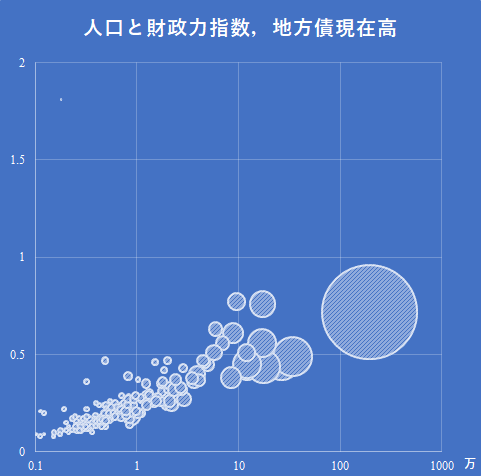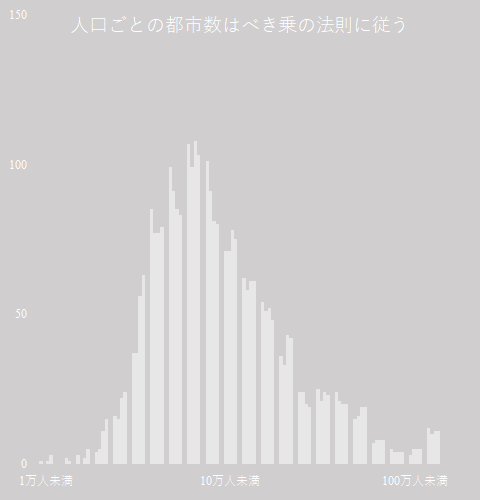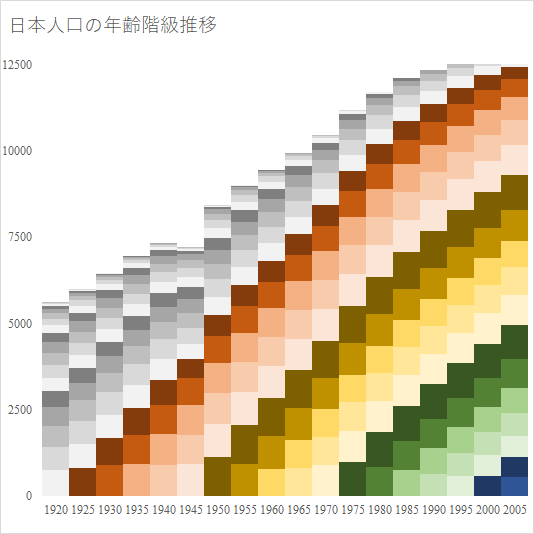
人口統計は最も重要な基幹統計の一つである.総務省の e-Stat は確かに有用であるが,かゆいところに手が届かない.例えば「市区町村ごと,年齢5歳階級ごとの人口構成の国勢調査ごとの推移を知りたい」という要求には全く無力である.
主として技術的な理由によるものと,統計調査の粒度の細かさによる.技術的な理由としては,データベースの画面表示セル数の上限を容易に超えてしまうデータ量になってしまうことである.しかし,根本的な理由は調査の粒度の細かさである.
2005 年以前と 2010 年以降とでは調査の精度が違う.今後は高精度なデータファイルが e-Stat に掲載されていくものと思われるが,2005 年以前に関しては都道府県より細かい粒度は存在しない.そこを求めると手作業になってしまい,現実的ではない.国立社会保障・人口問題研究所ならデータを持っているかもしれない.
2020 年は国勢調査の年にあたる.総務省にはできるだけ細かい粒度でのデータ掲載を望むものである.