前回の記事では階乗の自然対数を求めるユーザー定義関数をSQL Serverで作成するを記述した.今回はそのユーザー定義関数を用いてFisherの直接確率を求めるストアドプロシージャを記述する.
Fisherの直接確率を求めるストアドプロシージャをSQL Serverで定義する


Co-evolution of human and technology
前回の記事では階乗の自然対数を求めるユーザー定義関数をSQL Serverで作成するを記述した.今回はそのユーザー定義関数を用いてFisherの直接確率を求めるストアドプロシージャを記述する.
Fisherの直接確率を求める際,階乗の計算が必要になる.しかし,引数が最大でも170までと使い勝手が良くない.これはプログラム言語の種類にかかわらず,データ長の制約が原因である.今回は対数を用いて階乗計算の引数の限界を超えるアイデアを共有したい.
2020 年の国勢調査の結果がようやくeSTATに反映された.日本の市区町村よりも粒度の細かい小地域(町丁・字等別)の人口構成が公表されたのは2022年6月24日付である.今回はこのデータをSQL Serverに取り込んでみたい.
“eSTATの小地域(町丁・字等別)毎の年齢(5歳階級、4区分)別、男女別人口をSQL ServerにBULK INSERTする” の続きを読む
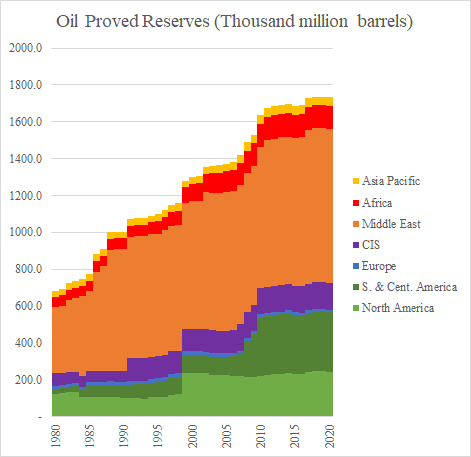
これまで日本の石油輸入元の推移,世界の石油生産量の推移を見てきた.石油は今後どれくらい採掘できるのか.ピークオイルという言葉は石油の供給には限界があるという意味で使われ始めたが,現時点では石油の需要のほうが先にピークアウトしそうであるという意味で使われ始めている.
石油の可採年数は40年前からずっとあと40年と言われ続けてきた.可採年数とは確認埋蔵量を年間生産量で除して求める.年間生産量は確かに増加傾向を示しているが,シェールオイルの発見,新たな油田の発見により,それを上回るペースで確認埋蔵量は増加傾向を示しており,結果として可採年数は長期化する傾向にある.